A results-oriented technologist with over 17 years of experience leading IT strategy, digital transformation, and DevOps across web development, server administration, and Agile project management. Proven expertise in designing and implementing high-impact technology solutions that align with business goals and drive growth, profitability, and operational excellence. Strong track record in ensuring robust information security frameworks to support business objectives. I have successfully led cross-functional teams from project conception to completion, optimizing performance and delivering on contractual and financial goals. My approach emphasizes collaboration, fostering partnerships with key stakeholders across operations to ensure shared success. Fluent in aligning technology roadmaps with business vision, I’m committed to driving innovation, scalability, and sustainable growth. I thrive in dynamic environments where technology drives competitive advantage and business transformation.
A Hands‑On Review of Amazon Q’s Custom Rules for Shift‑Left Governance
Spoiler: in less than an hour I transformed two plain‑English Markdown files into 22 actionable findings that Amazon Q surfaced directly in VS Code.
Why This Matters
Modern engineering teams already live in their IDEs and CI pipelines; meanwhile security, compliance and architecture guidance too often sits in PDFs or wikis that no one reads until audit time. Amazon Q’s new Custom Context Rules feature collapses that gap by letting you drop Markdown rulebooks into a special folder (.amazonq/rules/). The AI assistant then enforces those rules every time you:
run q chat from the CLI,
trigger a pull‑request check, or
ask the VS Code extension for a code review.
In other words, your policies become a first‑class, executable artifact – just like the infrastructure and application code they protect.
The Setup
1 — A Sample Three‑Tier Terraform Stack
For my demo I spun up a classic three‑tier app in Terraform: VPC, public & private subnets, an ALB, an EC2 web tier, RDS PostgreSQL and a handful of S3 buckets.
2 — Two Markdown Rulebooks
I authored two documents and placed them under best‑app‑ever/.amazonq/rules/:
File
Purpose
well-architected.md
A distilled version of the AWS Well‑Architected Framework. I kept the built‑in five pillars and tagged each bullet with a priority code ([P1], [P2], [P3]).
company-rules.md
EuroFinBank (my fictional FinServ) regulations layered on top – e.g. PSD2, GDPR, DORA, internal tagging standards and sustainability goals.
## Pillar: Operational Excellence
- **[P1]** Perform operations as code.
- **[P1]** Make frequent, small, reversible changes.
...
## Pillar: Governance & Compliance (EuroFinBank)
- **[P1]** Maintain a centralized AWS Landing Zone with guardrails codified via AWS Control Tower & Service Catalog.
- **[P1]** Enforce tagging policies (cost center, data sensitivity, regulatory domain) via Organization SCPs.
- **[P1]** Record & version all IaC in a secure Git repo with restricted merge approvals.
📸 Screenshot 1 (left pane) shows well-architected.md with the familiar blue headings rendered in VS Code.
Running the Review
A. From the CLI
$ q chat "review the code in my current directory recursively and respond with P1 findings only."
Amazon Q parsed both rulebooks, walked the entire Terraform tree and replied with a concise list of Priority‑1 violations:
Security Group Configuration:0.0.0.0/0 ingress for SSH. Violates “Apply security at all layers”.
Missing Resource Tagging: No cost‑center or data‑sensitivity tags. Violates EuroFinBank P1 tagging mandate.
Plaintext Database Credentials: Environment variables instead of Secrets Manager. Triggers CWE‑798 & Well‑Architected “Protect data at rest and in transit.”
CloudTrail Disabled: No org‑wide audit trail. Breaks EuroFinBank traceability requirement.
Encryption Not Enabled: RDS, EBS & S3 left unencrypted. Violates both frameworks.
Q suggested a one‑liner fix for every item, including ready‑to‑copy Terraform snippets.
B. Inside VS Code
Open the Command Palette → “Amazon Q: Review Workspace”.
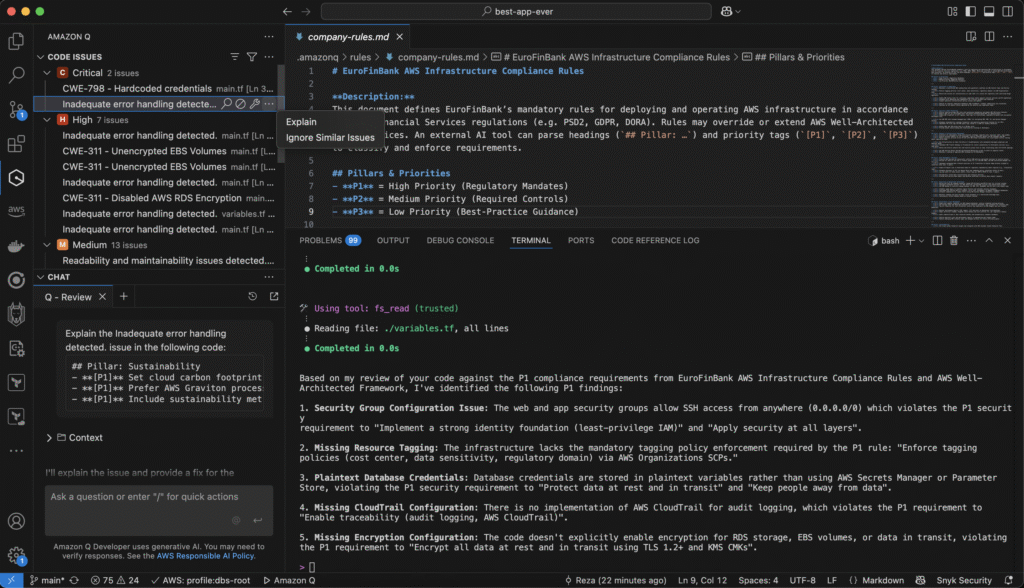
The extension lit up the Problems panel with 99 findings. In the Amazon Q side bar I could drill into:
Critical (2):
CWE‑798 – Hard‑coded credentials (pointing to main.tf line 30).
Inadequate error handling detected… – Amazon Q flagged an empty catch {} in a Lambda module.
High (7) – multiple unencrypted volumes, disabled RDS encryption, etc.
Medium (13) – readability, maintainability, and naming consistency tips.
📸 Screenshot 3 captures the moment: severity badges, CWE identifiers, quick‑fix icons and even a “Explain” hover action.
A single click on Explain opened a chat tab with an in‑context rationale and step‑by‑step remediation guidance – all without leaving the editor. Talk about developer ergonomics!
What I Learned (Key Take‑Aways)
Lesson
Why It’s Interesting
Policies as Code ≠ Code as Law
You don’t need to translate prose into OPA or Sentinel on day one. Amazon Q happily ingests plain English. Start simple, iterate.
Priority Tags Drive Focus
The [P1]/[P2]/[P3] convention lets leadership decide what’s non‑negotiable. Engineers see only P1 blockers when they’re in a hurry, but can expand to best practice tips later.
Shift‑Left Compliance Is Now Drag‑and‑Drop
Placing a new Markdown file in .amazonq/rules/ is literally all it takes to roll out a fresh policy across every repo. No pipeline re‑wiring required.
Human‑Readable, Audit‑Friendly
Auditors love narrative. With these files committed to Git, you have an immutable timeline of when each rule was introduced or updated – perfect for SOC 2 change management evidence.
Extensible to CI/CD
The same CLI command can run in GitHub Actions, CodeBuild or Jenkins, turning pull requests red if a new commit regresses on P1 rules.
Security & Sustainability Under One Roof
My EuroFinBank doc even includes sustainability pillars (e.g., “Prefer Graviton processors”). Amazon Q doesn’t care – if it’s a bullet, it’s a rule.
Final Thoughts
Amazon Q’s Custom Context Rules feel like linting for your entire operating model. The barrier to entry is almost comically low – just write Markdown. Yet the payoff is huge: unified guidance, faster reviews, happier auditors and, ultimately, safer releases.
If you already use the Well‑Architected Framework, start by pasting your favorite pillar into a rule file. If you’re in a regulated industry, carve‑out your compliance handbook section‑by‑section. Then let Amazon Q do the policing so your engineers can stay focused on shipping value.
Containers have completely transformed how I approach building, deploying, and managing applications. Their lightweight nature and ability to encapsulate dependencies have made them the foundation of my modern development workflows. When I discovered AWS Bottlerocket, a Linux-based operating system (OS) from Amazon Web Services, it felt like the perfect match for optimizing and securing containerized environments. Let me share my experience with what it is, its capabilities, and why I think it’s worth considering.
What is AWS Bottlerocket?
AWS Bottlerocket is an open-source, minimalist OS tailored specifically for running containers. Being open-source means that Bottlerocket benefits from community-driven contributions, which ensures regular updates and innovation. This aspect also allows businesses and developers to customize the OS to meet their specific needs, offering unparalleled flexibility. Open-source adoption fosters a sense of transparency and trust, making it easier for organizations to audit the code and adapt it for their unique use cases, which is especially valuable in sensitive or highly regulated environments. Unlike traditional operating systems that come with a variety of software packages, Bottlerocket is stripped down to include only what is necessary for container orchestration. This design reduces the attack surface and simplifies management.
Key Capabilities
Container-First Architecture Bottlerocket is designed from the ground up to run containers efficiently. Its architecture eliminates the overhead of traditional OS features that are unnecessary for containerized workloads. By focusing solely on container support, Bottlerocket ensures better performance and compatibility with orchestration tools like Kubernetes and Amazon ECS. This container-first approach streamlines operations, enabling developers and DevOps teams to focus on application performance rather than OS management.
Atomic Updates Managing OS updates is a common pain point in production environments. Bottlerocket simplifies this process with its image-based atomic update mechanism, which differs from traditional OS update methods that often involve package-level updates. With traditional approaches, updates can be inconsistent, leading to dependency issues or partial updates that destabilize the system. Bottlerocket’s image-based updates, on the other hand, apply changes in a single, atomic operation, ensuring consistency and making it easier to roll back in case of errors. This approach not only improves reliability but also minimizes downtime, which is critical for maintaining production workloads. This approach ensures that updates are applied in one go, reducing the risk of partial updates that could destabilize the system. Atomic updates also minimize downtime, as the entire system can be rolled back to a previous version in case of any issues. This consistency in updates improves reliability and simplifies maintenance.
Built-in Security Features Security is a top priority in containerized environments, and Bottlerocket addresses this with several built-in features. The OS uses a read-only root filesystem, which significantly reduces the risk of unauthorized changes. For instance, during one of my deployments, I realized that having a read-only root filesystem prevented a malicious script from overwriting critical system files. This feature ensures that even if an attacker gains limited access, they cannot easily tamper with the OS or compromise its integrity. Additionally, SELinux is enforced by default, providing mandatory access controls that enhance security. Bottlerocket’s minimalist design reduces the number of components, thereby limiting potential vulnerabilities and making it easier to secure the environment.
Integration with AWS Ecosystem For businesses already leveraging AWS services, Bottlerocket offers seamless integration with tools like Amazon EKS, ECS, and AWS Systems Manager (SSM). This tight integration simplifies deployment and management, allowing teams to use familiar AWS interfaces to control and monitor their containerized workloads. This makes Bottlerocket an ideal choice for organizations heavily invested in the AWS ecosystem.
Open-Source and Extensible As an open-source project, Bottlerocket is accessible to developers who want to customize it to suit their specific needs. The community-driven nature of the project ensures regular updates, improvements, and a robust support network. Businesses can extend Bottlerocket’s functionality or adapt it to unique requirements, providing flexibility for a wide range of use cases.
Why Use AWS Bottlerocket?
Enhanced Security The OS’s design prioritizes security by reducing potential vulnerabilities through its minimalistic architecture and advanced security features. This makes it a safer choice for running containerized workloads in environments where data protection is critical.
Operational Efficiency With features like atomic updates and AWS integration, Bottlerocket reduces the operational complexity associated with managing containerized environments. This enables teams to focus on scaling and optimizing their applications rather than spending time on infrastructure management.
Optimized for Containers Unlike traditional operating systems that cater to a broad range of applications, Bottlerocket is purpose-built for containers. This specialization results in better performance, streamlined workflows, and fewer compatibility issues, making it ideal for containerized applications.
Cost Savings By simplifying operations and reducing downtime, Bottlerocket helps businesses save on operational costs. Its integration with AWS services further reduces the need for additional tools and infrastructure, offering a cost-effective solution for containerized environments.
Community and Support As an AWS-supported project with an active community, Bottlerocket benefits from continuous improvements and a wealth of resources for troubleshooting and customization. This ensures businesses can rely on a stable and evolving platform.
Who Should Use AWS Bottlerocket?
Startups and Enterprises: Businesses looking for a secure, efficient, and scalable OS for containerized applications.
DevOps Teams: Teams aiming to simplify container orchestration and management.
Cloud-Native Developers: Developers building applications specifically for Kubernetes or Amazon ECS.
Integrating AWS Bottlerocket into existing development workflows was a surprisingly smooth process for me. That said, it wasn’t entirely without challenges. Initially, I struggled with ensuring Bottlerocket’s SELinux policies didn’t conflict with some of my custom container images. Debugging these issues required a deep dive into policy configurations, but once resolved, it became a learning moment that improved my security posture. Another hurdle was aligning Bottlerocket’s atomic update process with my CI/CD pipeline’s tight deployment schedules. After a bit of fine-tuning and scheduling updates during lower-traffic periods, I was able to integrate Bottlerocket without disrupting workflows. These challenges, while momentarily frustrating, were ultimately outweighed by the long-term operational benefits Bottlerocket provided. Since Bottlerocket is designed with container-first principles, it fit seamlessly into my ECS setups (yes, I do not have a production Kubernetes cluster in my personal account 😀 ). I started by using Bottlerocket on nodes in my test Amazon EKS setups, and its built-in compatibility with AWS Systems Manager made the configuration and monitoring straightforward. The atomic update mechanism also helped ensure that updates to the OS didn’t disrupt ongoing workloads, a critical feature for me and anyone’s CI/CD pipelines. Adopting Bottlerocket didn’t just simplify OS management—it also improved security and reduced the operational overhead I used to deal with when managing traditional operating systems in containerized environments.
AWS Bottlerocket is a game-changer for containerized environments because it combines a purpose-built design with exceptional security and operational benefits. Its seamless integration with AWS tools, support for atomic updates, and container-first architecture make it stand out from traditional operating systems. By reducing operational overhead and improving reliability, Bottlerocket addresses key challenges faced by teams managing containerized workloads. These unique features make it an excellent choice for developers and organizations looking to optimize their containerized application environments. Its purpose-built nature, combined with security and operational benefits, makes it an excellent choice for organizations leveraging containers. Whether you’re running workloads on Amazon EKS, ECS, or other Kubernetes environments, Bottlerocket is worth considering for your next project.
In today’s digital world, ensuring your software is secure and trustworthy is more important than ever. With supply chain attacks becoming more common, code signing is one effective way to protect your software. In this article, I will walk you through what code signing is, why it’s essential, and how AWS Signer can help you do it at scale—while also keeping up with regulations like the EU’s DORA act.
What Is Code Signing?
Code signing is a process that ensures your software, like an app or script, hasn’t been changed or tampered with since the original author signed it. Essentially, it adds a digital signature to your code, which lets users or systems verify that the code is authentic and comes from a trusted source.
Code signing uses cryptographic techniques to embed a unique digital signature, which helps verify both the publisher’s identity and the software’s integrity. This means users can trust the code they’re running, protecting them from any malicious changes that could compromise security.
Why Should Code Be Signed?
Code signing is crucial for a few reasons:
Security and Trust: The signed code shows that it comes from a legitimate source and hasn’t been altered since it was signed. This helps build user trust and reduces the chances of running compromised software.
Protection Against Tampering: Unsigned code can be vulnerable to tampering by malicious actors. Code signing helps prevent this by providing a verification mechanism.
Compliance: Many regulations and standards require software to be signed to ensure it follows best practices for security and compliance.
Code Signing Requirements in EU’s DORA Act
The Digital Operational Resilience Act (DORA) in the European Union sets strict requirements for financial institutions to secure their software supply chain. Under DORA, financial entities must ensure that their IT systems are secure, authentic, and trustworthy. Specifically, Article 15 of DORA requires that all critical software components be digitally signed to ensure integrity and authenticity. Code signing plays a key role here, as it helps organizations verify that the software they deploy hasn’t been altered and is from a trusted source.
Having a robust code-signing practice is crucial for companies aiming to meet these regulatory requirements and improve their cybersecurity posture. This is where AWS Signer comes in.
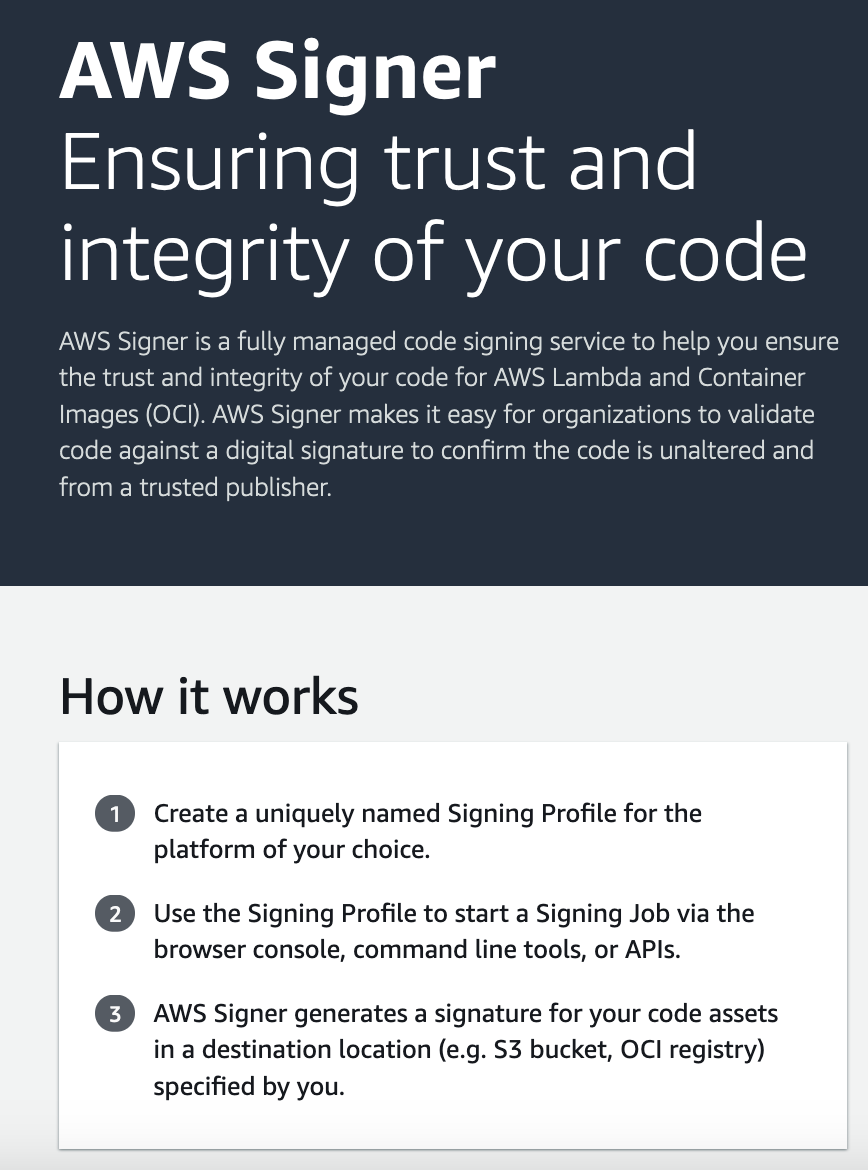
What Is AWS Signer?
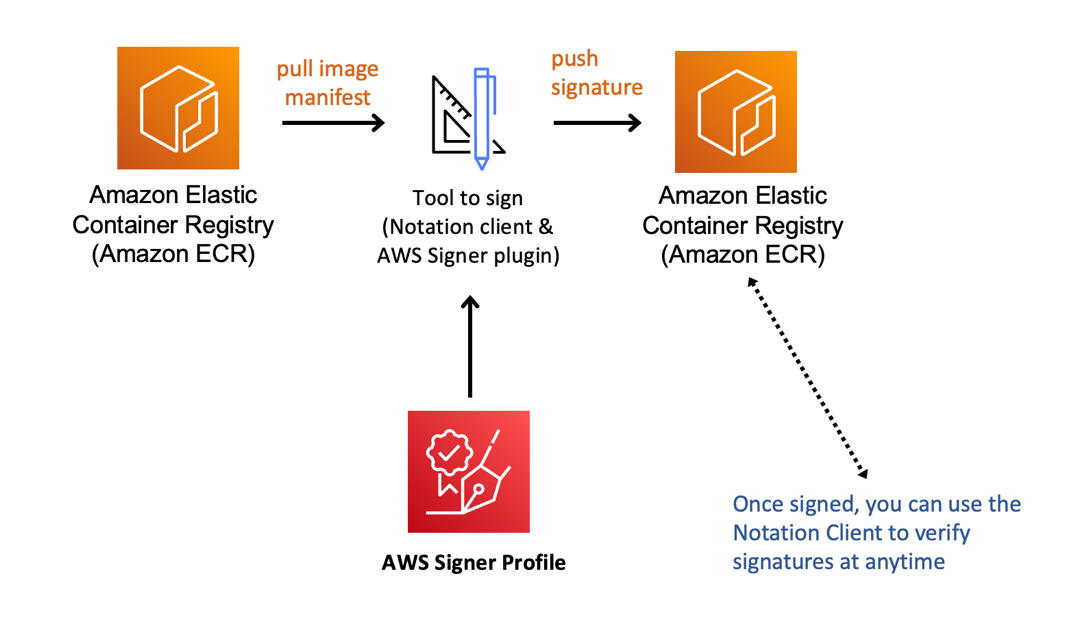
AWS Signer is a fully managed code-signing service that helps you protect your software’s integrity by digitally signing it and ensuring it hasn’t been tampered with. With AWS Signer, security teams can define and manage the code-signing environment from one central place, making creating, maintaining, and auditing the signing process much more manageable.
AWS Signer integrates with AWS Identity and Access Management (IAM) to handle permissions for signing and with AWS CloudTrail to track who generates signatures, which can help meet compliance needs. AWS Signer reduces the operational burden of manually handling certificates by managing both the public and private keys used in the code-signing process.
How to Use AWS Signer at Scale
Scaling code signing effectively can be challenging, especially for organizations with many applications and teams. AWS Signer has several features that make this easier:
Centralized Key Management: AWS Signer works with AWS Key Management Service (KMS), allowing you to easily generate and manage signing keys securely.
Automated Workflows: You can automate signing workflows using AWS Step Functions or integrate with CI/CD tools like AWS CodePipeline to make sure every build is signed before deployment.
Compliance Tracking: With AWS CloudTrail integration, AWS Signer makes it simple to audit who signed what, which is key for regulatory compliance and internal governance.
For larger organizations, this centralized and scalable approach ensures that every piece of software across different teams and projects meets security and compliance standards. This is especially important for financial services companies that comply with regulations like DORA.
CI/CD Integration with AWS Signer
To maximize the benefits of code signing, integrating AWS Signer into your Continuous Integration and Continuous Deployment (CI/CD) pipeline is a great approach. This ensures that every code is signed automatically as part of your build and deployment processes, reducing manual effort and minimizing the risk of unsigned code slipping through. By integrating AWS Signer into your CI/CD pipeline, you can ensure that all your software releases are signed consistently and reliably.
CI/CD Integration with AWS Signer and Notary
To maximize the benefits of code signing, integrate AWS Signer into your Continuous Integration and Continuous Deployment (CI/CD) pipeline. This ensures that every piece of code is signed automatically as part of your build and deployment processes, reducing manual effort and minimizing the risk of unsigned code slipping through. If you use custom CI/CD solutions, you can leverage the AWS CLI or AWS SDK to interact with AWS Signer and add signing as part of your custom build or deployment scripts.
The Notary Project is an open-source initiative that aims to provide a platform-independent and secure way to sign, store, and verify software artifacts, such as container images. Originally developed by Docker, Notary aims to ensure the integrity and authenticity of distributed software by allowing users to establish trust through digital signatures.
In this article, I will be using Notary. Ensure that you have downloaded and installed Notary from here: https://notaryproject.dev/
Before using the example below, you must ensure that a singer profile is created:
To integrate AWS Signer with GitHub Actions, you can create a workflow that signs your code after building it. Here’s an example of how to do it:
name: Sign Code with AWS Signer
on:
push:
branches:
- main
jobs:
sign-code:
runs-on: ubuntu-latest
steps:
- name: Checkout code
uses: actions/checkout@v2
- name: Set up AWS CLI
uses: aws-actions/configure-aws-credentials@v2
with:
aws-access-key-id: \${{ secrets.AWS_ACCESS_KEY_ID }}
aws-secret-access-key: \${{ secrets.AWS_SECRET_ACCESS_KEY }}
aws-region: eu-central-1
- name: Build the code
run: |
# Add your build commands here
echo "Building code..."
- name: Sign the code with AWS Signer
run: |
aws signer start-signing-job \
--profile default \
--source "S3={"bucketName":"your-bucket","key":"your-code.zip"}" \
--profile-name "your-profile" \
--destination "S3={"bucketName":"signed-code","prefix":"signed/"}"
In this example, the workflow checks out the code, sets up AWS credentials, builds the code, and then signs it using AWS Signer.
In a world where cyber threats are constantly growing, code signing isn’t just a best practice—it’s essential for keeping your software supply chain secure. A managed solution like AWS Signer can make code signing easier, help you meet regulatory requirements, and, most importantly, protect the organization and its customers from software supply chain attacks.
Ready to boost your software security? Start exploring AWS Signer today and make code signing a core part of your software development process.
Make sure to read this blog post on AWS before actually implementing the singer in your environment: https://aws.amazon.com/blogs/security/best-practices-to-help-secure-your-container-image-build-pipeline-by-using-aws-signer/
In Part 1, Part 2, Part 3, and Part 4, I covered the legal basis, backup strategy, policy implementation, locking the recovery points stored in the vault, applying vault policy, legal holds, and audit manager to monitor the backup and generate automated reports.
In this part, I will explore two essential topics that are also DORA requirements: restore testing and Monitoring and alarming.
Restore Testing
Restore testing was announced late last year on Nov 27, 2024. It is extremely useful and one component that can ease the operational overhead of backups.
…[Restore Testing] helps perform automated and periodic restore tests of supported AWS resources that have been backed up…customers can test recovery readiness to prepare for possible data loss events and to measure duration times for restore jobs to satisfy compliance or regulatory requirements.
Doesn’t that sound amazing? You can practically automate the health check of the backups, including snapshots and continuous recovery points, and ensure they are restorable. Furthermore, you can indeed have a record of restore duration and, based on that, provide the policies and procedures submitted to auditors that are 100% aligned with the reality of the infrastructure.
By using restore testing, you can use the Audit Manager feature to generate compliance reports on the restoration of recovery points.
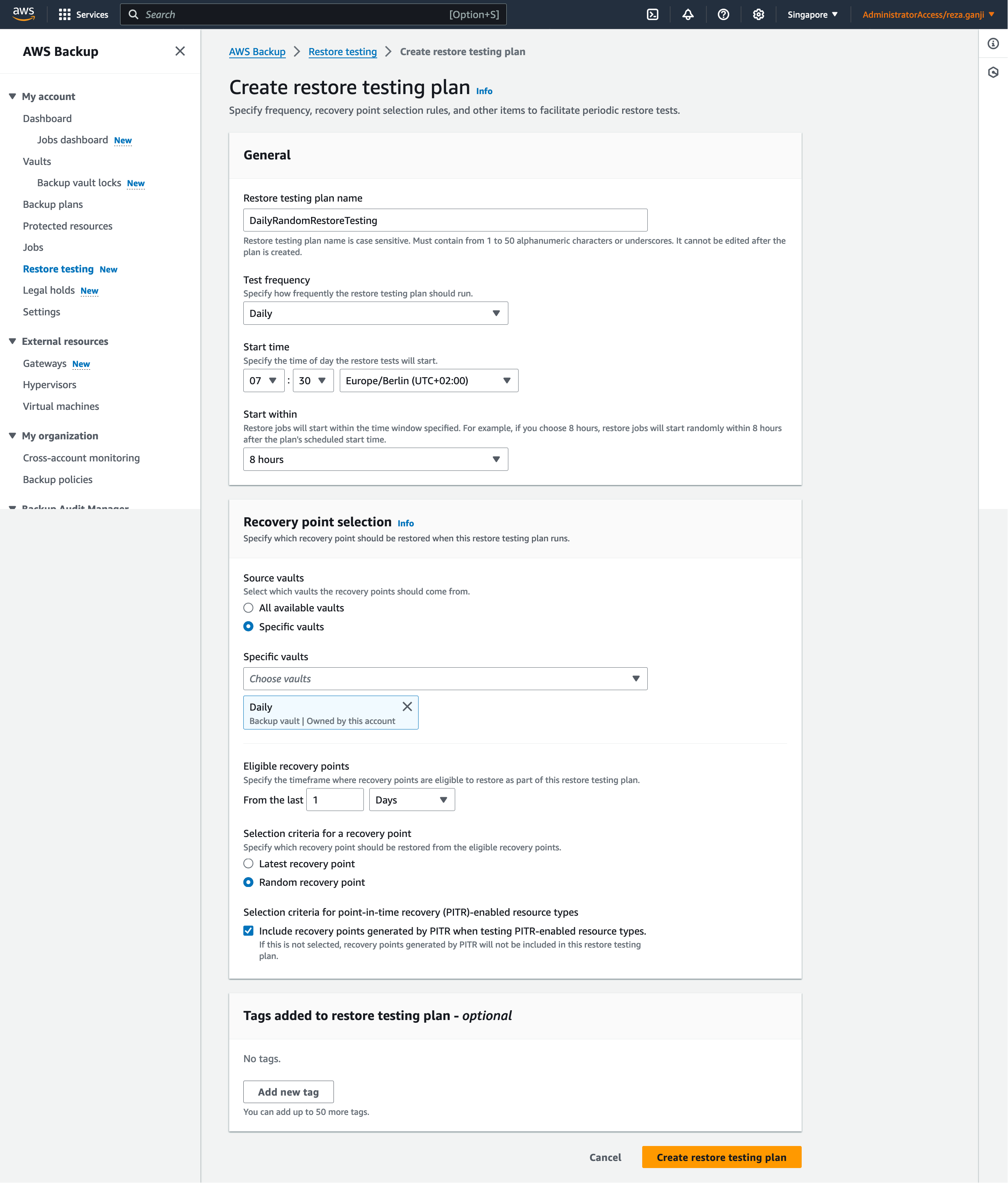
To get started with restore testing, go to the Backup console, and from the navigation sidebar, click on Restore Testing. Then click on “Create restore testing plan”.
Once the restore plan is created, you will be redirected to the resource selection page. One important note is that each resource type would require specific metadata to allow AWS Backup to restore the resource correctly.
Important:
AWS Backup can infer that a resource should be restored to the default setting, such as an Amazon EC2 instance or Amazon RDS cluster restored to the default VPC. However, if the default is not present, for example the default VPC or subnet has been deleted and no metadata override has been input, the restore will not be successful.
Resource type
Inferred restore metadata keys and values
Overridable metadata
DynamoDB
deletionProtection, where value is set to falseencryptionType is set to DefaulttargetTableName, where value is set to random value starting with awsbackup-restore-test-
encryptionTypekmsMasterKeyArn
Amazon EBS
availabilityZone, whose value is set to a random availability zone encrypted, whose value is set to true
availabilityZonekmsKeyId
Amazon EC2
disableApiTermination value is set to falseinstanceType value is set to the instanceType of the recovery point being restored requiredImdsV2 value is set to true
iamInstanceProfileName value can be null or UseBackedUpValueinstanceTyperequireImdsV2securityGroupIdssubnetId
Amazon EFS
encrypted value is set to truefile-system-id value is set to the file system ID of the recovery point being restored kmsKeyId value is set to alias/aws/elasticfilesystemnewFileSystem value is set to trueperformanceMode value is set to generalPurpose
kmsKeyId
Amazon FSx for Lustre
lustreConfiguration has nested keys. One nested key is automaticBackupRetentionDays, the value of which is set to 0
kmsKeyIdlustreConfiguration has nested key logConfigurationsecurityGroupIdssubnetIds, required for successful restore
Amazon FSx for NetApp ONTAP
name is set to a random value starting with awsbackup_restore_test_ontapConfiguration has nested keys, including: junctionPath where /name is the name of the volume being restored sizeInMegabytes, the value of which is set to the size in megabytes of the recovery point being restored snapshotPolicy where the value is set to none
ontapConfiguration has specific overrideable nested keys, including: junctionPathontapVolumeTypesecurityStylesizeInMegabytesstorageEfficiencyEnabledstorageVirtualMachineId, required for successful restoretieringPolicy
Amazon FSx for OpenZFS
openZfzConfiguration, which has nested keys, including: automaticBackupRetentionDays with value set to 0deploymentType with value set to the deployment type of the recovery point being restored throughputCapacity, whose value is based on the deploymentType. If deploymentType is SINGLE_AZ_1, the value is set to 64; if the deploymentType is SINGLE_AZ_2 or MULTI_AZ_1, the value is set to 160
kmsKeyIdopenZfsConfiguration has specific overridable nested keys, including: deploymentTypethroughputCapacitydiskiopsConfigurationsecurityGroupIdssubnetIds
Amazon FSx for Windows File Server
windowsConfiguration, which has nested keys including: automaticBackupRetentionDays with value set to 0deploymentType with value set to the deployment type of the recovery point being restored throughputCapacity with value set to 8
kmsKeyIdsecurityGroupIdssubnetIdsrequired for successful restorewindowsConfiguration, with specific overridable nested keys throughputCapacityactiveDirectoryIdrequired for successful restorepreferredSubnetId
availabilityZones with value set to a list of up to three random availability zones dbClusterIdentifier with a random value starting with awsbackup-restore-testengine with value set to the engine of the recovery point being restored
dbInstanceIdentifier with a random value starting with awsbackup-restore-test-deletionProtection with value set to falsemultiAz with value set to falsepubliclyAccessible with value set to false
destinationBucketName with a random value starting with awsbackup-restore-test-encrypted with value set to trueencryptionType with value set to SSE-S3newBucket with value set to true
Note that Restore Testing is account specific and cannot be configured at the organization level yet. This would mean, you will need to apply this configurations to all accounts across the organization or to all accounts that require automatic restore testing.
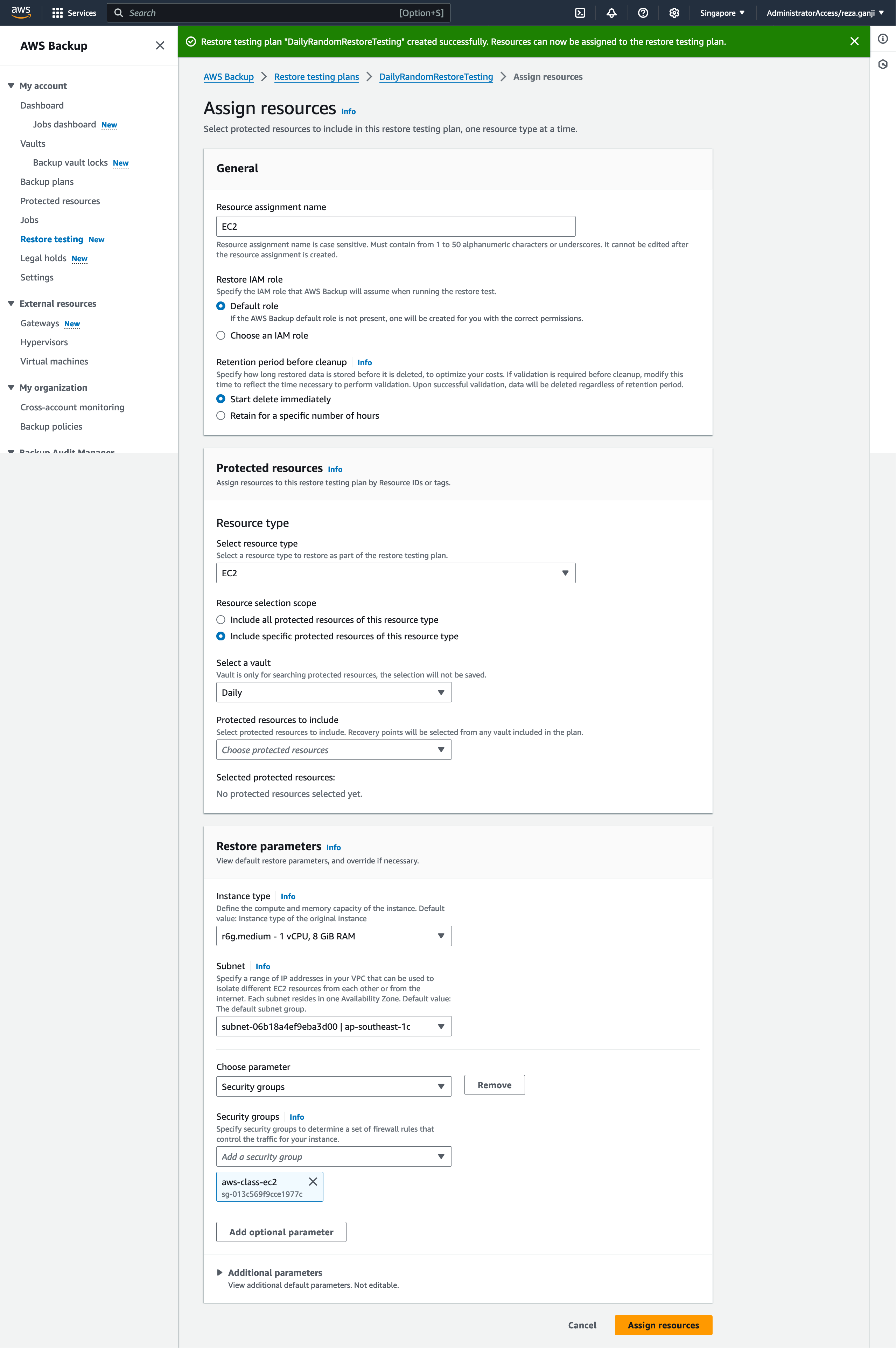
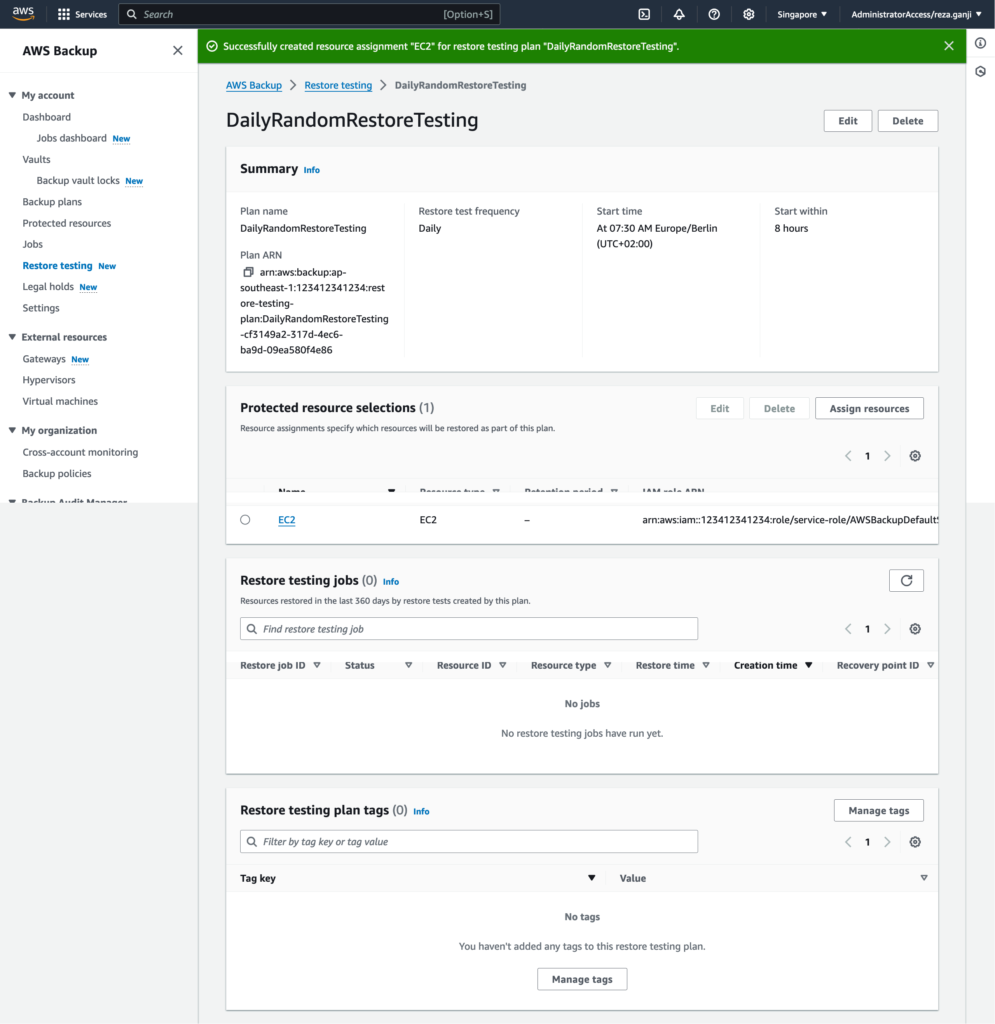
Let’s create a resource selection or assignment for the restore plan:
As you can see, based on the resource type that I have selected, I must provide specific configurations. In this case, I selected the resource type EC2 and I selected a subnet that I will be using for restore testing only which is isolated and does not interfere with my production environment and it does not have access to the internet both inbound and outbound.
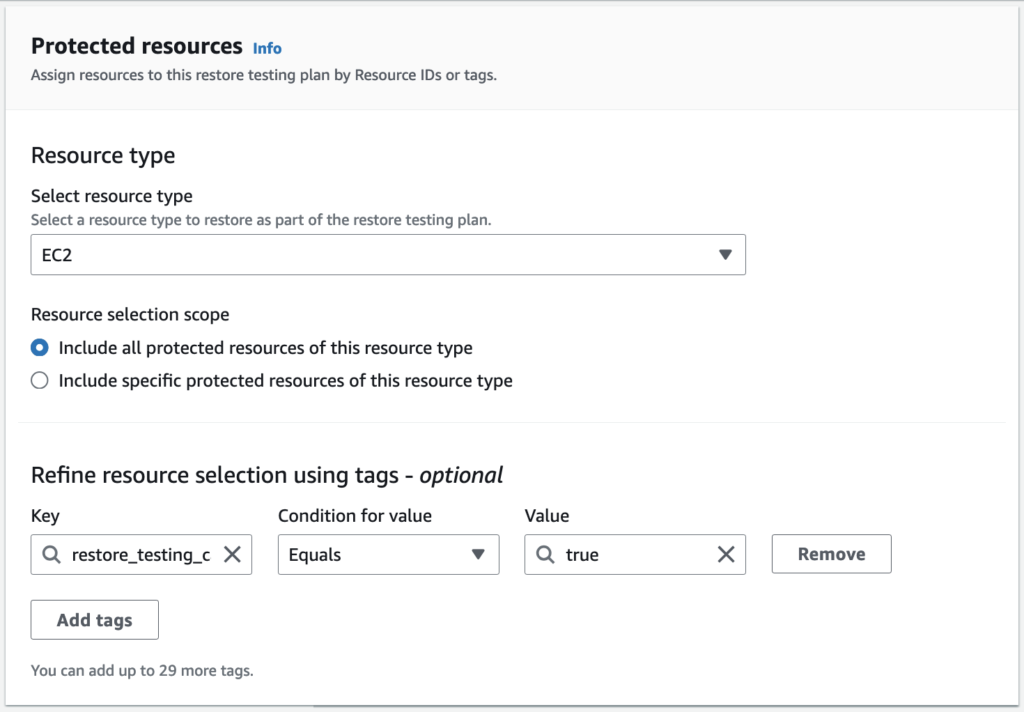
Optionally, you can always tag your resources based on their type for easier selection of resource types. In part 2, I created a tag called restore_testing_candidate = true to be used explicitly for this part. By having that tag, I know which resources within my infrastructure are meant to go through the audit and require a restore testing compliance report. By using the tag AWS Backup Restore Testing tag selection, I can only include the specific resources:
And finally, this is how my restore testing will look like:
I configured the restore testing jobs to start at 7:30 AM and start within 8 hours. During this period, monitor the EC2 quota if a large number of instances are being restored via restore testing. Watch out for the failure monitoring in the next section.
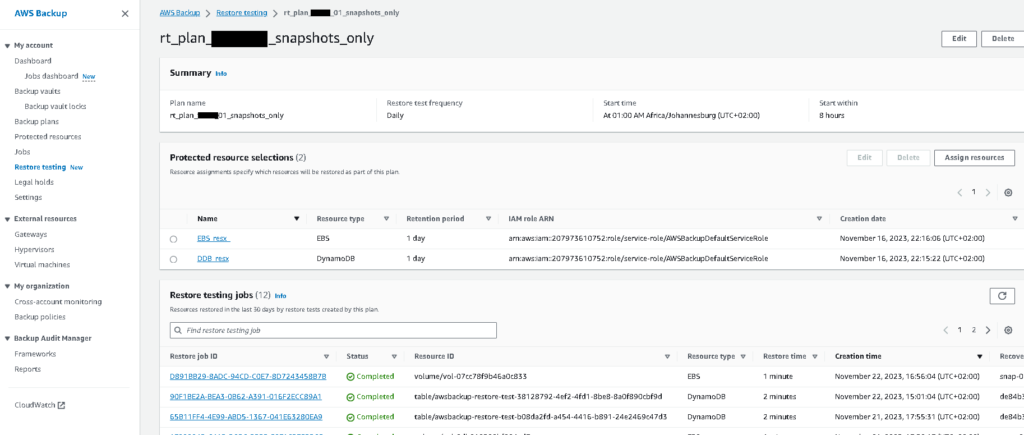
Once the restore testing jobs get executed, you will be able to view the job together with the history:
AWS Backup policy configured at the org level is limited to tags for resource selection.
Do not enable the vault lock before you are 100% certain all the backup configurations are accurate.
Read all the limitations and requirements carefully, particularly about the backup schedule and not including a single resource in two backup policies.
Configure everything with IaC to ensure it can be reapplied and changed easily across the org.
Backup Monitoring
There are multiple ways to monitor the backup jobs, which I will go through them all:
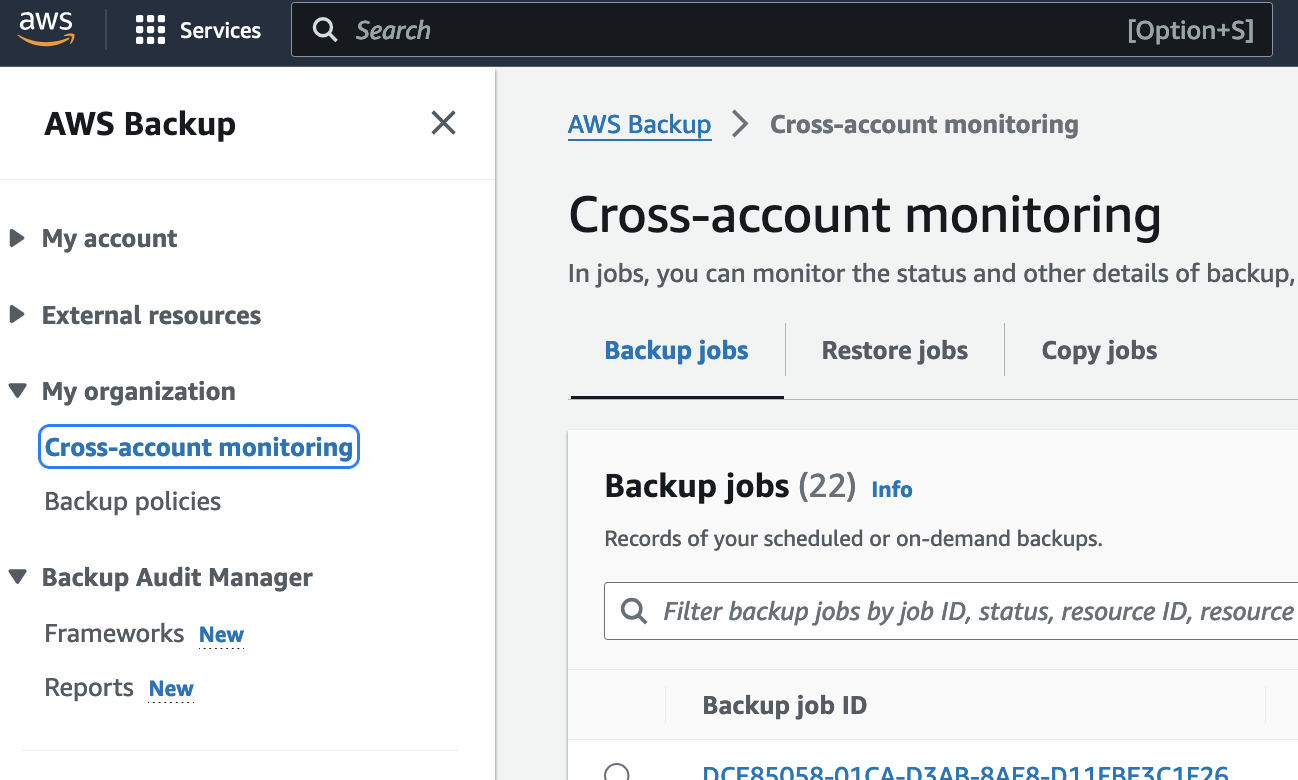
Cross-account monitoring
Jobs Dashboard
CloudWatch
Cross-account monitoring
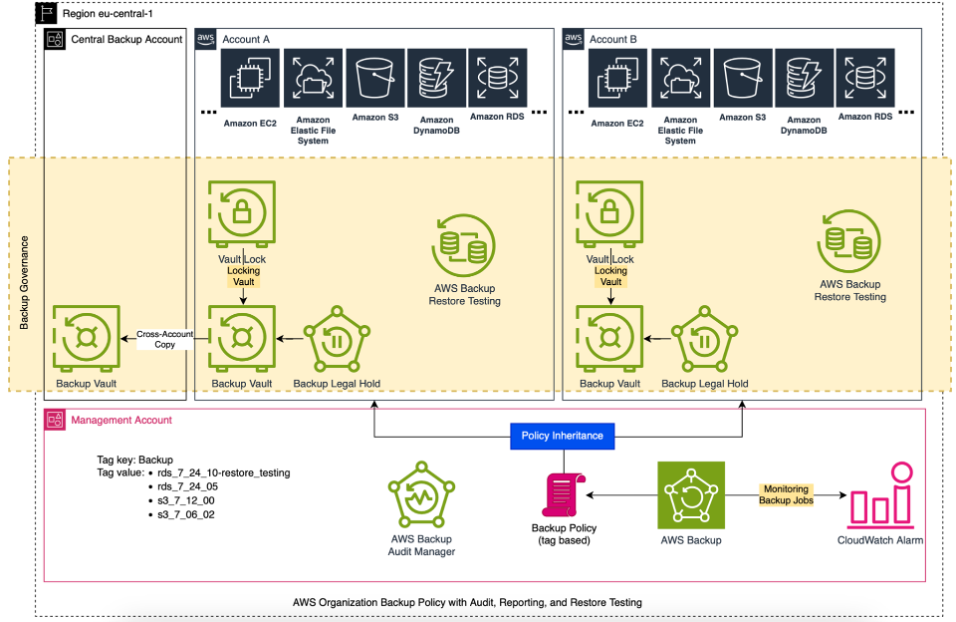
Cross-account monitoring provides the capability to monitor all backup, restore, and copy jobs across the organization from the root or backup delegated account. Jobs can be filtered by job ID, job status (failed, expired, etc.), resource type, message category (access denied, etc.), or account ID.
One of the biggest advantages is the centralized oversight it provides. Instead of having to log in to each AWS account separately to check backup jobs and policies, AWS Backup Cross-Account Monitoring gives me a unified view of metrics, job statuses, and overall resource coverage. This kind of visibility is a game-changer for keeping tabs on backup health and ensuring compliance across the board. It’s also incredibly useful for policy enforcement. I can define backup plans at an organizational level and apply them consistently across all accounts. This helps me sleep better at night, knowing that the data protection standards I’ve set up are being followed everywhere, not just in one account.
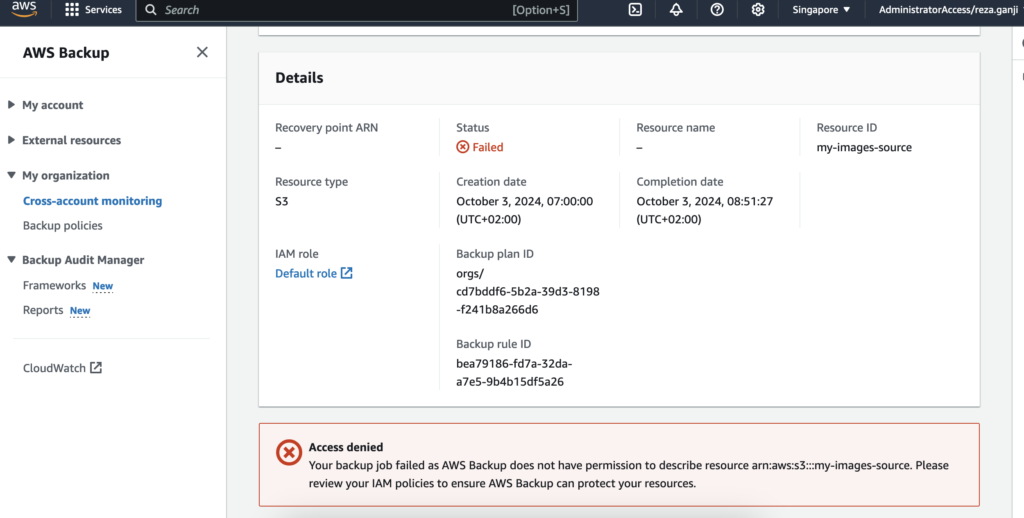
I have a failed job in my cross-account monitoring. Let’s have a quick look at it:
At the bottom of each failed backup job you will be able to see the reason that caused the job to fail. In this case, the role that was used by AWS Backup does not have sufficient privilege to access the S3 bucket.
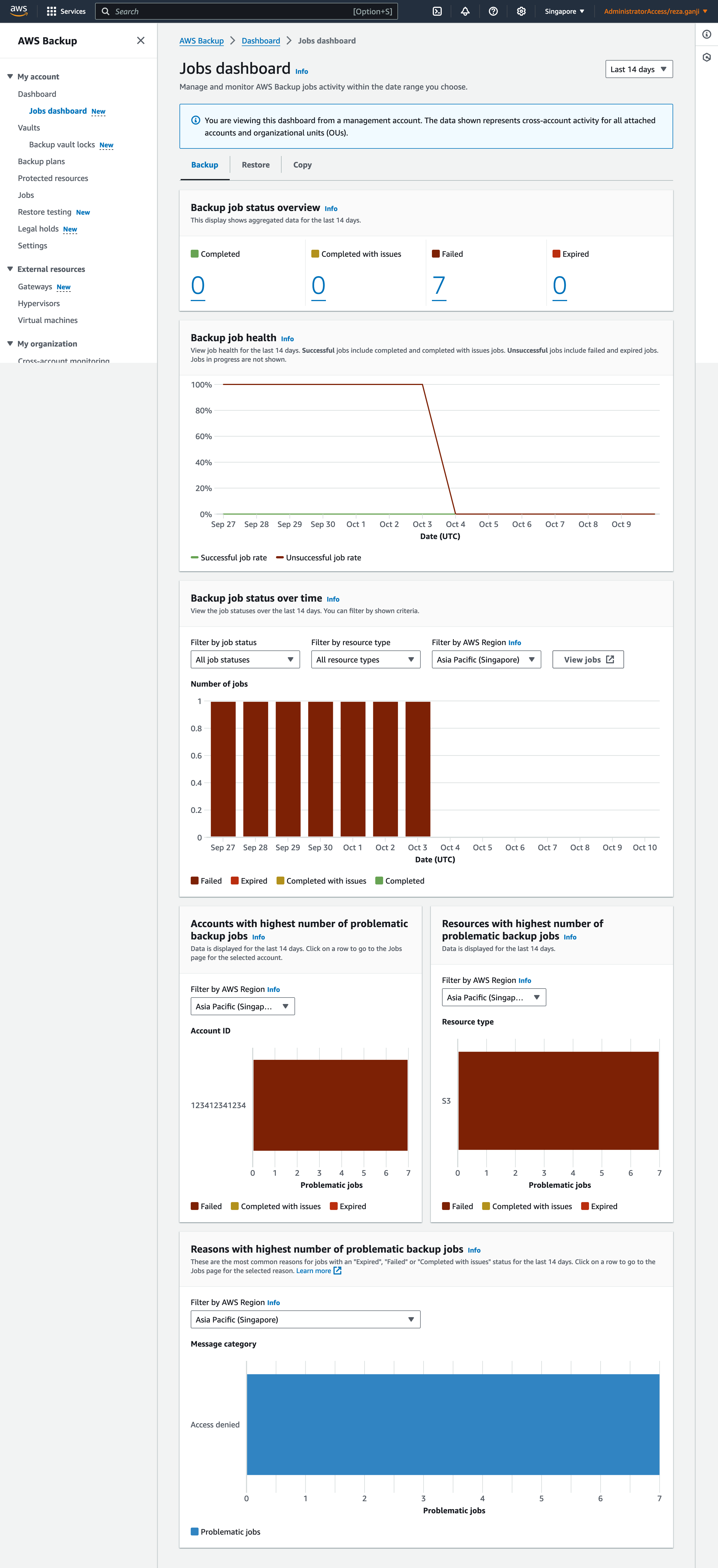
AWS Backup Jobs Dashboard
AWS Backup Jobs Dashboard is another tool I often find myself using. It provides a clear and detailed view of backup and restore jobs, allowing me to track the progress of each task. But how does it differ from AWS Backup Cross-Account Monitoring? Let’s break it down. The AWS Backup Jobs Dashboard gives me a real-time overview of all the backup and restore activities happening within a single AWS account. This includes details like job status, success rates, and any errors that might come up. It’s essentially my go-to interface when I need to understand what’s happening with backups right now—whether jobs are running, succeeded, failed, or are still pending.
This dashboard helps me monitor individual jobs, troubleshoot any issues immediately, and ensure my backup schedules are running smoothly. It’s all about real-time monitoring and operational control within a particular account.
For me, the Backup Jobs Dashboard is where I go when I need to get into the weeds—troubleshoot specific issues, track individual jobs, and make quick fixes. Cross-Account Monitoring, however, is where I zoom out to ensure the broader strategy is in place and working smoothly across all of AWS.
Backup Job Monitoring using CloudWatch
When managing backups, especially at scale, visibility is crucial. One of the tools that makes monitoring AWS Backup jobs more efficient is Amazon CloudWatch. By using CloudWatch with AWS Backup, I can set up a robust monitoring system that gives me real-time alerts and insights into my backup operations.
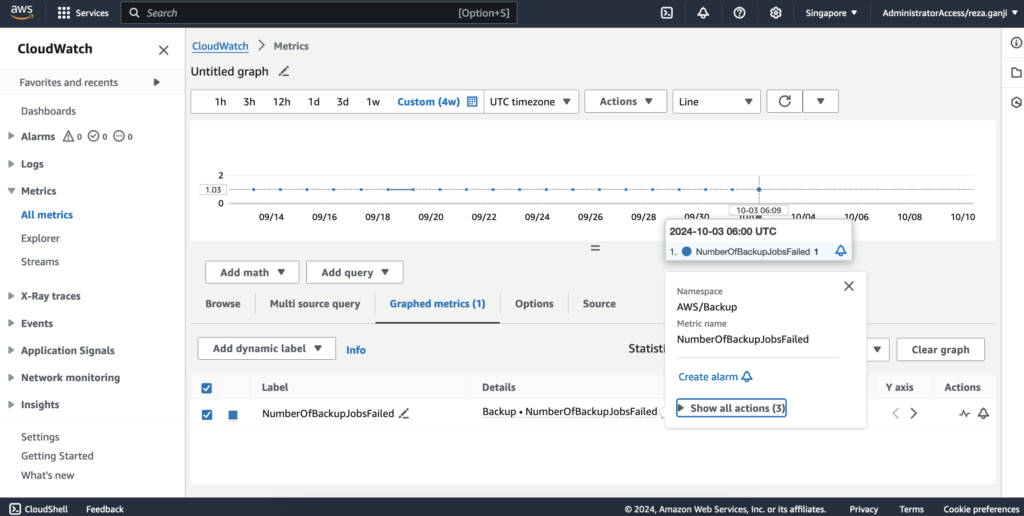
Amazon CloudWatch integrates seamlessly with AWS Backup to monitor all the activities of my backup jobs. With CloudWatch, I can collect metrics and set up alarms for different job statuses, like success, failure, or even pending states that take longer than expected. This means I don’t have to manually monitor the AWS Backup dashboard constantly—I can let CloudWatch handle that and notify me only when something needs my attention.
For example, if a critical backup fails, I can configure a CloudWatch Alarm to send me a notification via Amazon SNS (Simple Notification Service). That way, I can immediately jump in and resolve the issue. This level of automation helps keep my backup strategy proactive rather than reactive.
Another powerful aspect of using CloudWatch is automation with CloudWatch Events. I can create rules that trigger specific actions based on the state of a backup job. For example, if a backup job fails, CloudWatch can trigger an AWS Lambda function to retry the backup automatically or notify the relevant teams via Slack or email. This helps streamline the workflow and reduces the manual intervention needed to keep backups running smoothly.
The reason I like using CloudWatch with AWS Backup is simple—it’s all about proactive monitoring and automation. AWS Backup alone gives me good visibility, but when I integrate it with CloudWatch, I get the power of real-time alerts, customizable dashboards, and automated responses to backup events. This means fewer surprises, faster response times, and ultimately a more resilient backup strategy.
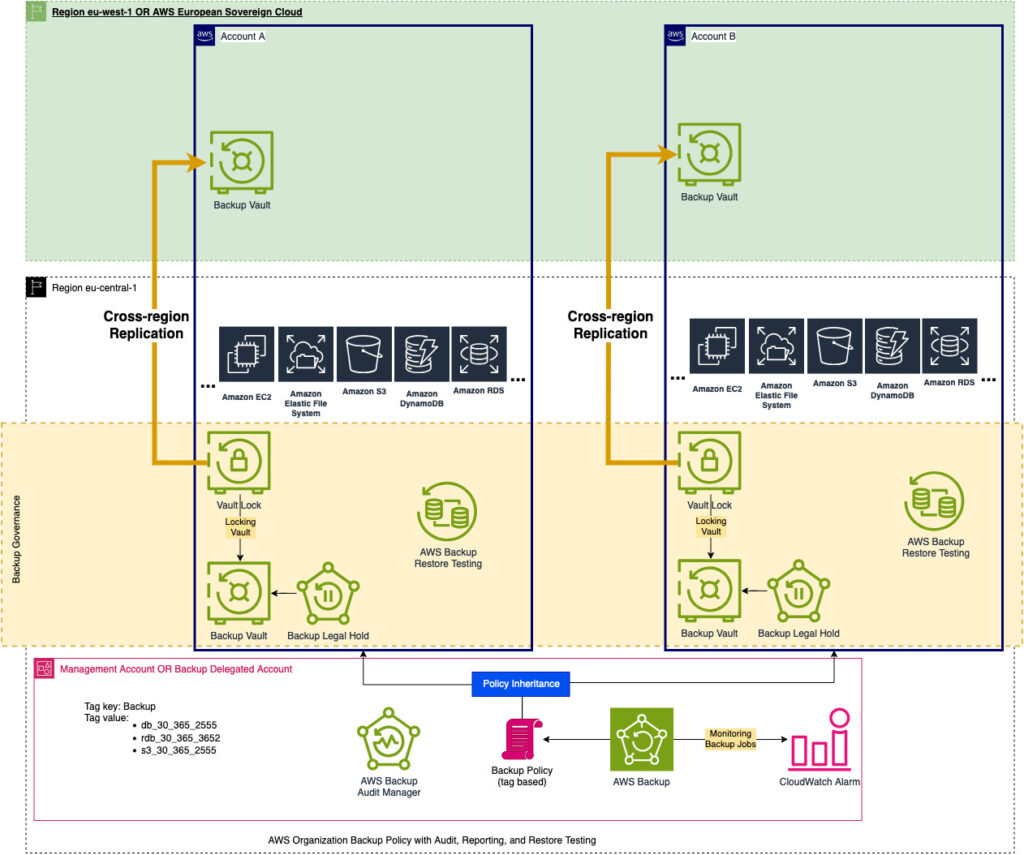
As a reminder, here is what the target architecture diagram looks like:
Closing Thoughts
Throughout this series, we have explored the comprehensive journey of achieving compliance with AWS Backup under the Digital Operational Resilience Act (DORA). We started by understanding the foundational requirements, from setting up backup strategies, retention policies, and compliance measures to implementing key AWS services such as Backup Vault, Vault Lock, Legal Holds, and Audit Manager. Each of these tools helps ensure that backup and restoration strategies not only meet regulatory standards but also provide operational resilience and scalability.
One of the highlights has been seeing how AWS Backup features, such as restore testing and automated compliance auditing, can reduce the manual effort and complexity associated with meeting DORA requirements. Restore testing allows us to perform automated health checks of our backups, ensuring recovery points are restorable and compliant without the need for manual intervention. Meanwhile, Audit Manager provides a powerful mechanism for generating and managing compliance reports that are crucial during audits.
Finally, monitoring and alarming using tools like AWS CloudWatch gives us proactive oversight of backup processes across accounts, ensuring that any failures or discrepancies are addressed promptly. With Cross-Account Monitoring, Jobs Dashboard, and CloudWatch integration, we can stay confident that our entire backup strategy remains operationally resilient and compliant.
Conclusion
In today’s evolving regulatory landscape, compliance and resilience are more important than ever—especially in the financial services industry, where data integrity and availability are critical. This series has emphasized not just the how but also the why behind building a robust backup strategy using AWS tools to meet DORA standards.
The digital financial landscape is only growing more complex, but by effectively leveraging AWS Backup services, we can ensure our cloud infrastructure remains resilient, compliant, and ready to handle any operational challenges that arise.
Thank you for joining me on this journey to master AWS Backup in the context of DORA compliance. I hope this series has provided you with the tools and insights needed to build a robust and scalable backup strategy for your organization.
In Part 1, Part 2, and Part 3, I covered the legal basis, backup strategy, policy implementation, locking the recovery points stored in the vault, and applying vault policy to prevent specific actions.
In this part, I will dive deeply into two essential compliance-related topics: Legal Holds and Audit Manager.
Legal Holds
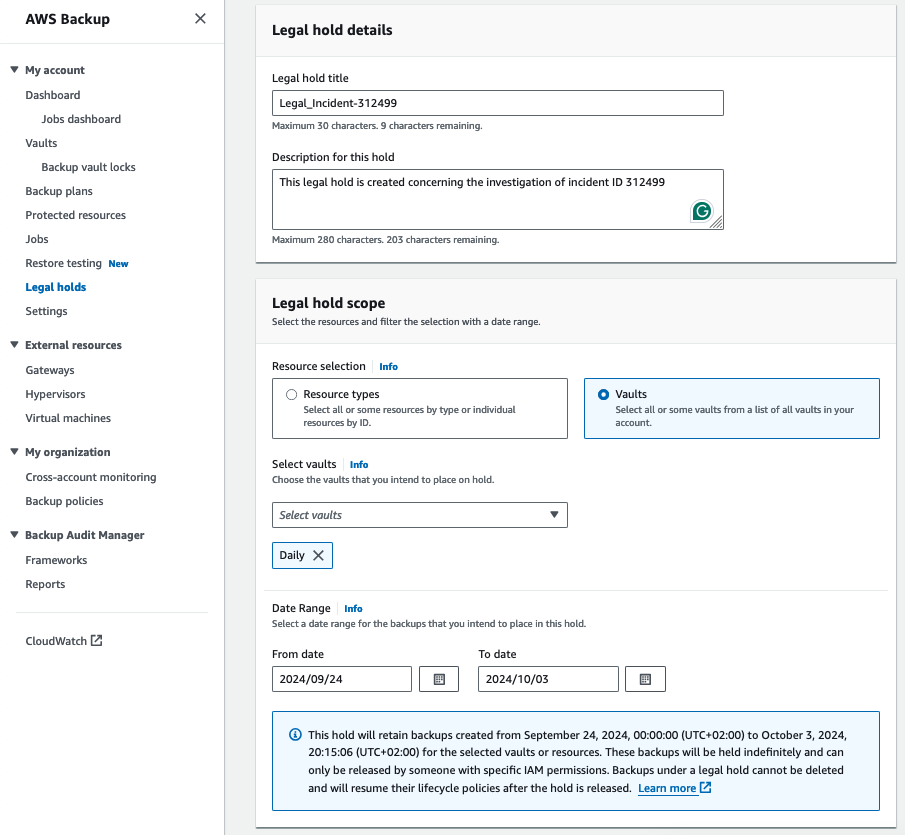
AWS Backup Legal Holds are designed to help comply with legal and regulatory requirements by preventing the deletion of recovery points that may be needed for legal purposes, such as audits, investigations, or litigation. Legal holds are the assurance that critical recovery points are retained and protected from being accidentally or intentionally deleted or altered. At first, this feature might sound similar to the Vault Lock feature, which also prevents deletion of the recovery points if the Vault is in compliance mode. The differences are:
Legal Holds can be modified or removed by a user with the proper privilege
Legal Holds tie the recovery point to a date range despite the lifecycle
Legal Holds can be applied to both Vaults and resource types categorically
You are limited to 50 scopes per legal hold
The Legal Holds’ date range might initially seem confusing, considering that the recovery points continue to be added to a specific vault. But the use case for Legal Holds differs!
Legal Holds can be helpful in use cases like the retention of specific resource types or recovery points stored in a particular vault to prevent them from being deleted if they backup was taken within the range. The Legal Holds date range is set in order to avoid the deletion of backups despite the lifecycle if the backup was taken within that range. For example, a data breach occurs, and the bank must investigate and report on the incident. Backups related to the breach are stored in an S3 bucket; the database snapshot and EBS volumes are all stored in the Daily vault and need to be preserved for both internal review and external reporting to regulators for the next two years from the date of the incident. In this scenario, Legal Holds can be used to protect the recovery points related to the investigation.
From the Backup console sidebar menu, navigate to Legal Holds and add a new Legal Hold.
All backups taken from 24.09.2024 until 03.10.2024 will be retained until the legal hold is removed.
It is also possible to add tags when creating a legal hold to make the protected resources more easily identifiable.
Audit Manager
AWS Backup Audit Manager was announced in 2021, and it is one of the most critical features for legal compliance and reporting on cloud infrastructure backup protection. Without the Audit Manager, a company must implement custom tools and scripts to provide a similar report to auditors and regulators.
Firstly, AWS Config must be enabled for Audit Manager Framework to function. The reason for requiring AWS Config is that the resource changes are tracked via Config, including resources deployed in an account, resources that are a part of a backup plan, etc.
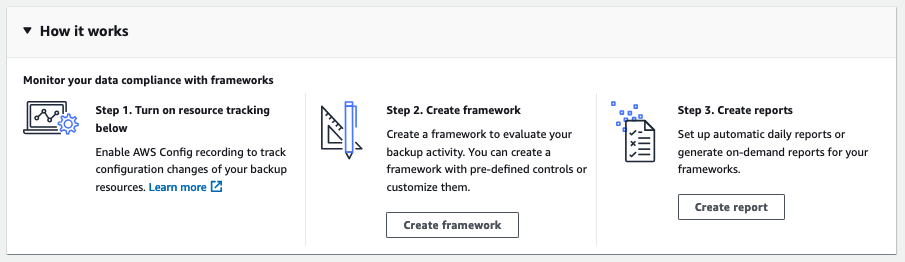
On the home page of Audit Manager Frameworks, you will see pretty good how-to-start steps:
Before creating a framework, let’s look at another feature of Audit Manager called Reports.
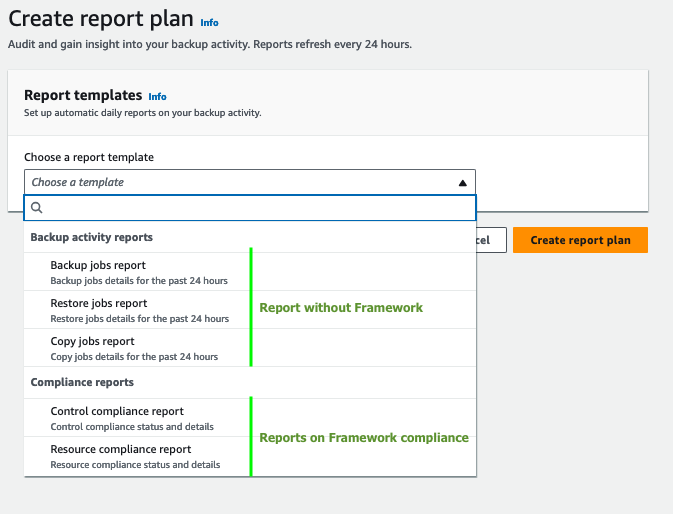
Report plans allow you to create recurring and on-demand reports to audit your backup activity, including cross-account and cross-Region reports.
Not all reports require a Framework. Here is how they work:
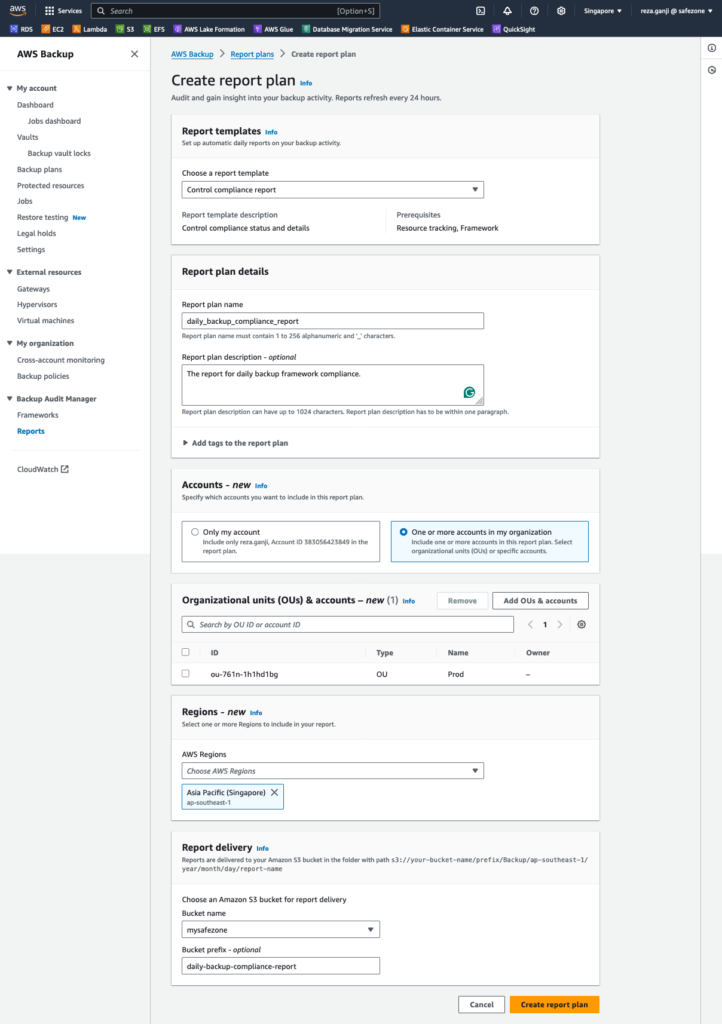
The two Compliance reports will report on the state of resources in conjunction with the pre-defined framework. You can look at the compliance framework as a representation of the organization’s backup policy written in a document.
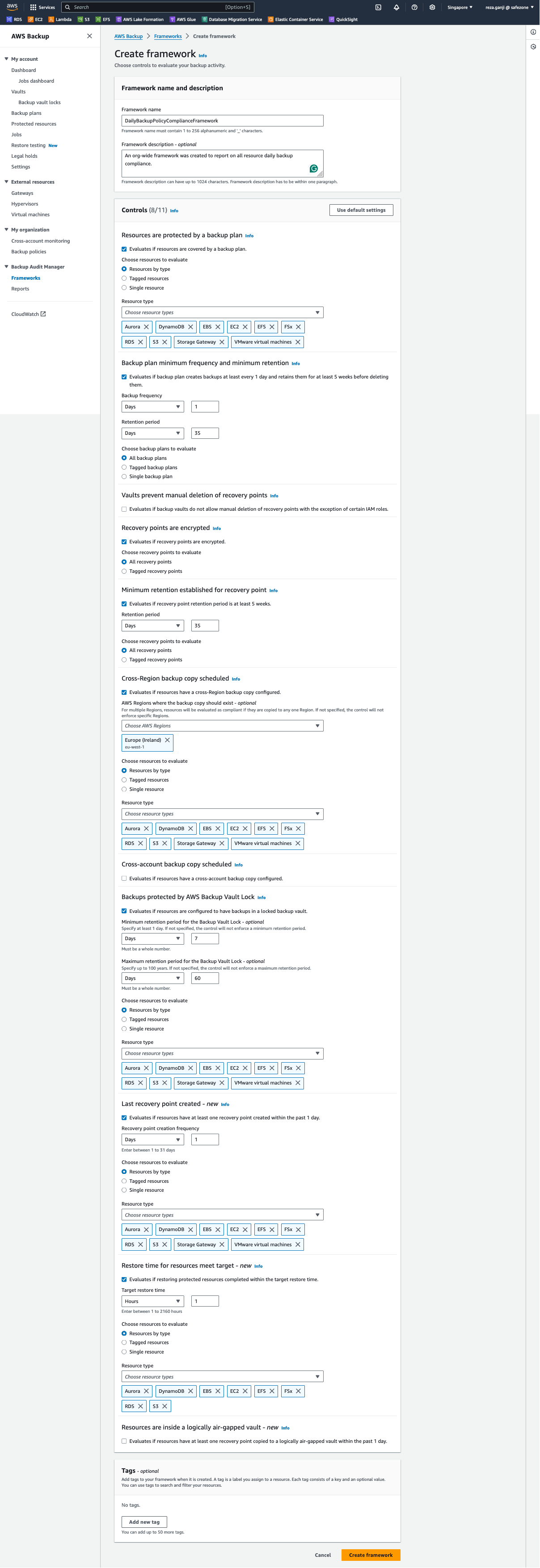
Let’s create a Framework to understand it better. I set a name for the Framework called PolicyComplianceFramework. There are 11 controls that can be configured:
Resources are protected by a backup plan
Backup plan minimum frequency and minimum retention
Vaults prevent manual deletion of recovery points
Recovery points are encrypted
Minimum retention established for recovery point
Cross-Region backup copy scheduled
Cross-account backup copy scheduled
Backups protected by AWS Backup Vault Lock
Last recovery point created – new
Restore time for resources meet target – new
Resources are inside a logically air-gapped vault – new
As you can see, the controls cover a reasonably wide range of evaluations. Each control can be configured independently based on a specific resource type, resource tag, or even a single resource.
I made some changes to the control settings to meet my backup policy compliance report requirements:
As you can see, I disabled these three controls and why:
Vaults prevent manual deletion of recovery points.
Evaluates if backup vaults do not allow manual deletion of recovery points with the exception of certain IAM roles.
Why disabled? All vaults must have a lock enabled in compliance modes, which does not allow deletion by design.
Cross-account backup copy scheduled
Evaluates if resources have a cross-account backup copy configured.
Why disabled? AWS Backup does not support cross-account AND cross-region copies of the recovery points simultaneously. I am copying the recovery points to another region, and as such, no cross-account copy is possible.
Resources are inside a logically air-gapped vault – new
Evaluates if resources have at least one recovery point copied to a logically air-gapped vault within the past 1 day.
Why disabled? I am not using air-gapped vaults as I prefer to control the recover points cross-region copy and its storage location.
After the framework is created, it will take some time to aggregate and evaluate the resources. As a reminder, frameworks cannot function without AWS Config.
Now that the audit framework is created, I will explain the Backup Report Plans.
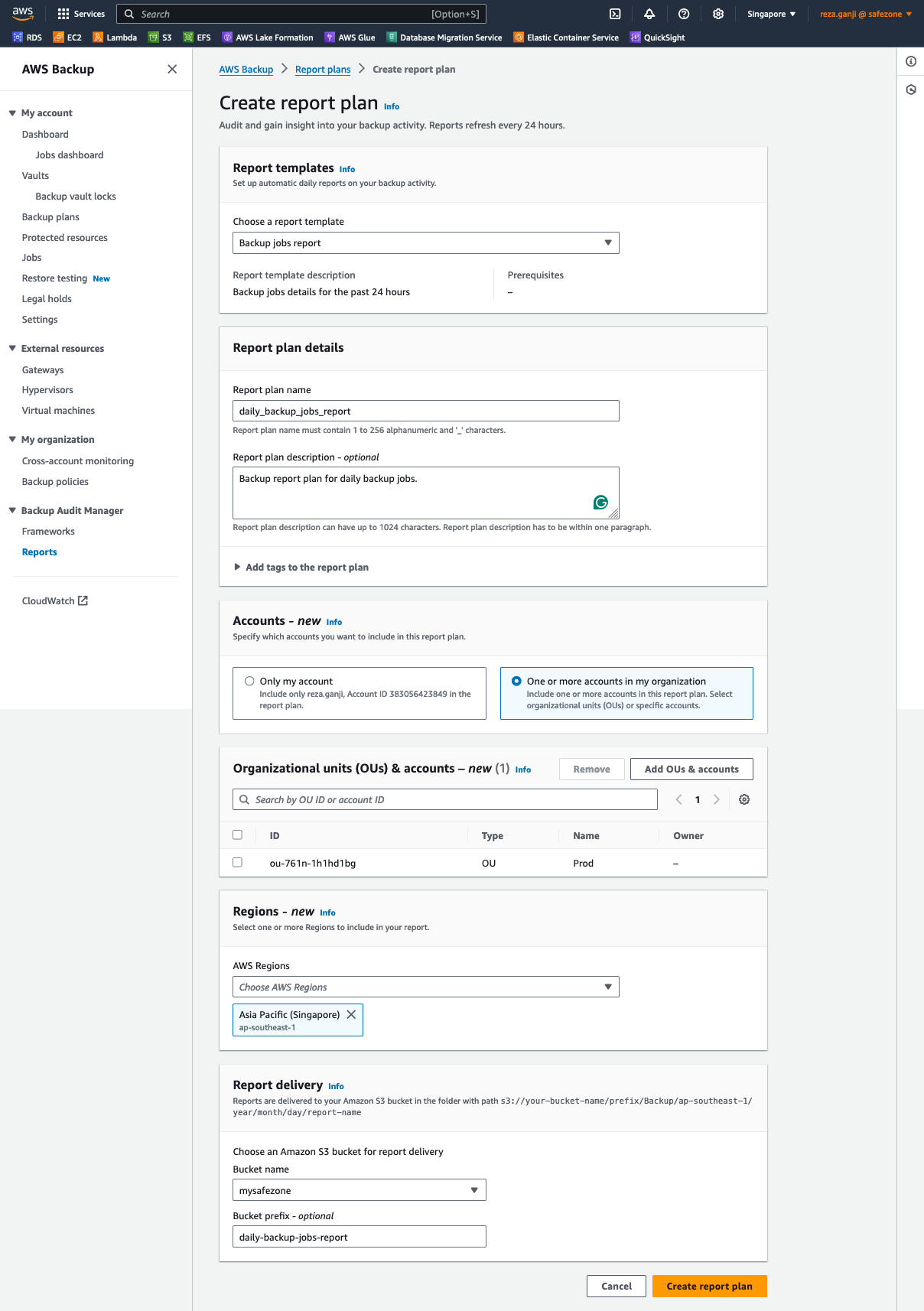
In almost every certification, and indeed, DORA included, the auditors will ask for a backup job report. A backup job report is one way to automate the report generation and ease the auditing process. You will need to decide which accounts and OUs are included in the job report and also need to create an S3 bucket to store the automatically generated reports.
With this report plan created, I can now provide the backup job success/failure report to auditors anytime. Also, I will make one more report that is linked to the framework that was created.
This report will be a compliance report to ensure that the resources are in compliance with all the resources covered in the backup policy. Similarly, you must configure the OUs and accounts in the report and an S3 bucket to store the daily report. The report refreshes every 24 hours.
In this part, we reviewed how AWS Backup Audit Manager works and how Legal Holds can be handy in specific use cases. Finally, we generated audit reports based on the created framework and stored the reports in an S3 bucket.
As a reminder, here is what the target architecture diagram looks like:
In the next part, I will elaborate on AWS Backup Restore Testing.
In Part 1 and Part 2, I covered the legal basis, backup strategies, and retention and briefly touched on vaults. In this part, I will cover policy creation in the root or backup delegated account, configuring Vaults & its compliance lock, legal holds, and resource selection.
Vaults Configuration
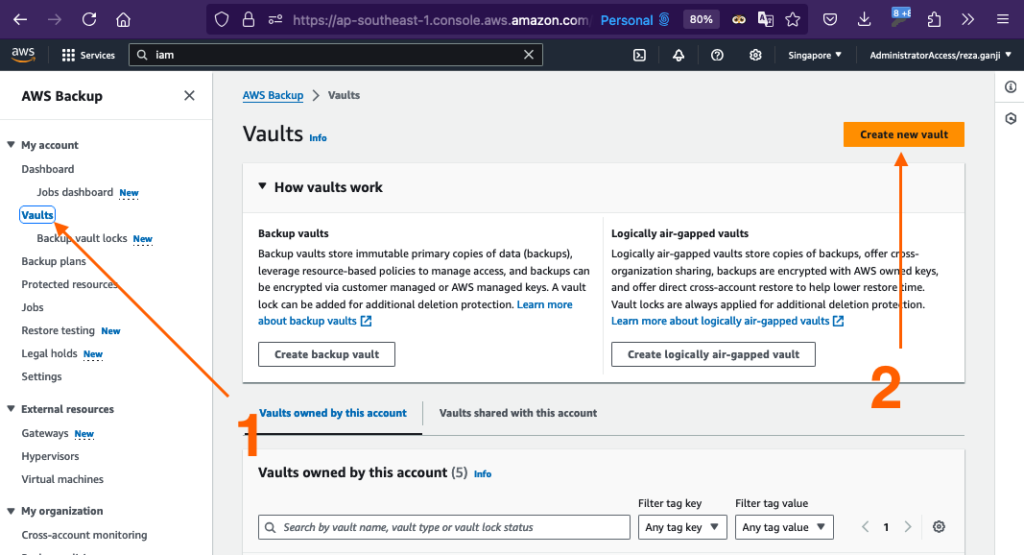
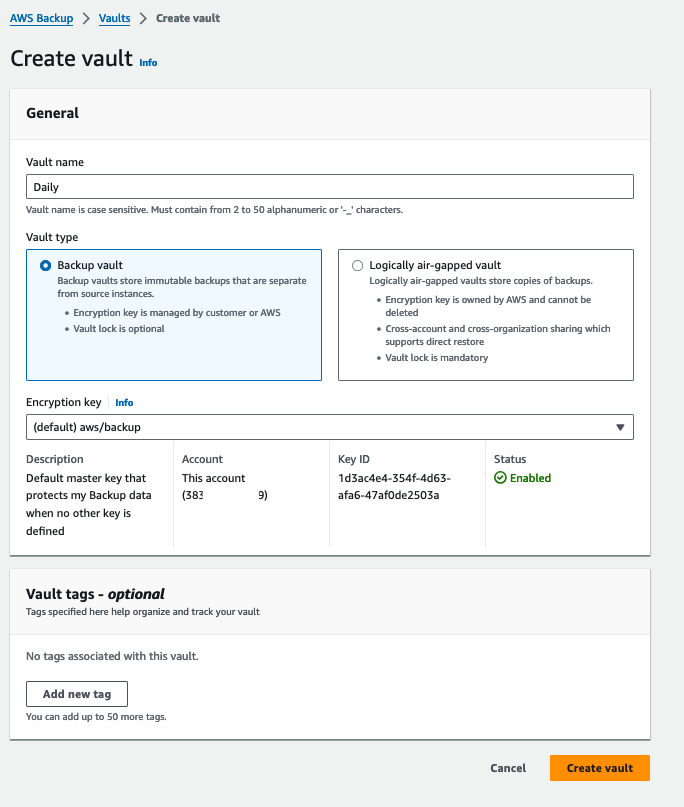
To begin with, let’s create three standard vaults for all the recovery points: daily, monthly, and yearly.
We’ll need to repeat this step for monthly and yearly vaults.
Once the vaults are created, we can add specific policies to them. Let’s not forget that one of DORA’s requirements is about who can access the recovery points, which also includes who can delete them. Click on all the vaults, edit the access policy, and add this policy:
As you can see, the policy denies anyone deleting the recovery points, starting a copy job (be it in the same account or any account outside the organization), and it prevents modification of recovery point lifecycle.
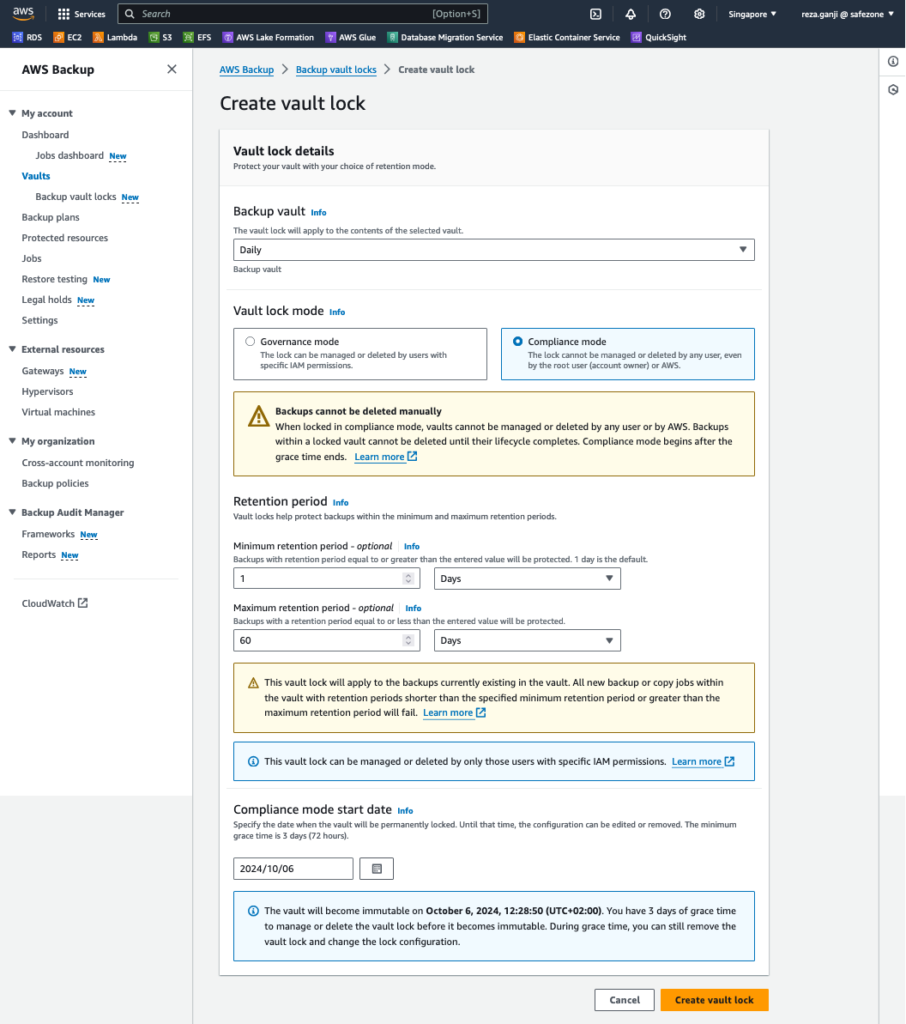
Vault Compliance Lock
Firstly, let’s explain what is Vault Compliance Lock, its variants, and features:
Backup vault is a container that stores and organizes your backups. When creating a backup vault, you must specify the AWS Key Management Service (AWS KMS) encryption key that encrypts some of the backups placed in this vault. Encryption for other backups is managed by their source AWS services.
What is Vault Lock?
A vault lock enforces retention periods that prevent early deletions by privileged users, such as the AWS account root user. Whether you can remove the vault lock depends on the vault lock mode.
How many modes of Vault Locks are there:
Vaults locked in governance mode can have the lock removed by users with sufficient IAM permissions.
Vaults locked in compliance modecannot be deleted once the cooling-off period (“grace time“) expires if any recovery points are in the vault. During grace time, you can still remove the vault lock and change the lock configuration.
Governance Mode allows authorized users some flexibility to modify or delete backups, while Compliance Mode locks down backups completely, preventing any changes until the retention period is over. Compliance Mode offers stricter control and is often used in environments requiring regulatory compliance. In contrast, the Governance Mode is more suitable for operational governance, where authorized personnel may still need to manage backups.
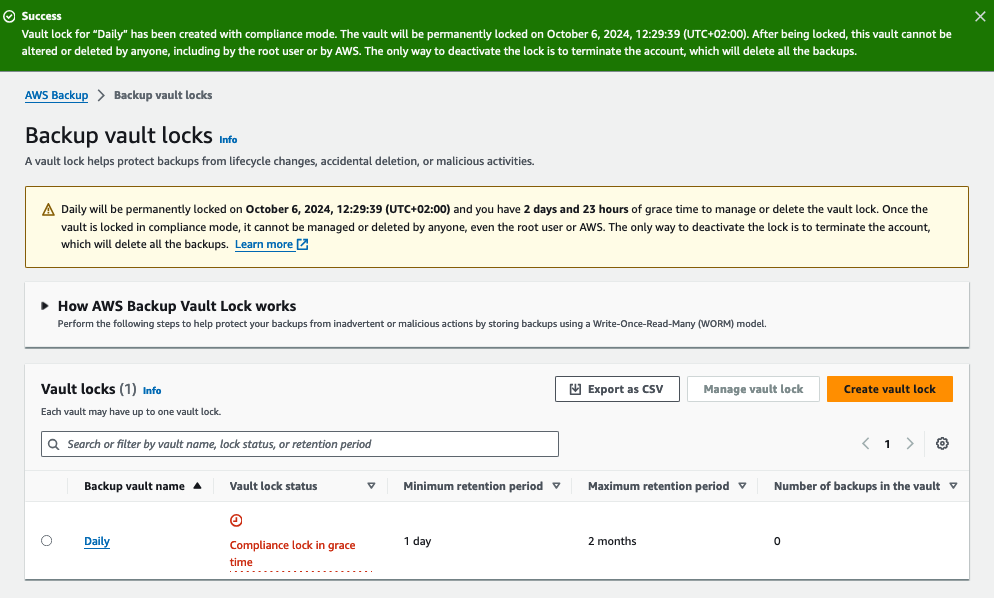
Let’s enable the Vault Lock in compliance mode. Why compliance? Because it simplifies the audit process and demonstrates the deletion protection, the auditors will not request additional proof if they are not already familiar with AWS Backup features.
Once the vault lock is created, it enters the state of “Compliance lock in grace time”. The message indicates that the lock can be deleted within the next three days.
Backup Policy Creation
As explained previously, you have two options:
Manage cross-account backup policies from the root account
Delegate an account to administer the backup policies
I will use the root account for policy creation as it is my test organization account. Still, it would be best if you tried to have a delegated administrator to avoid using the root account for day-to-day operations.
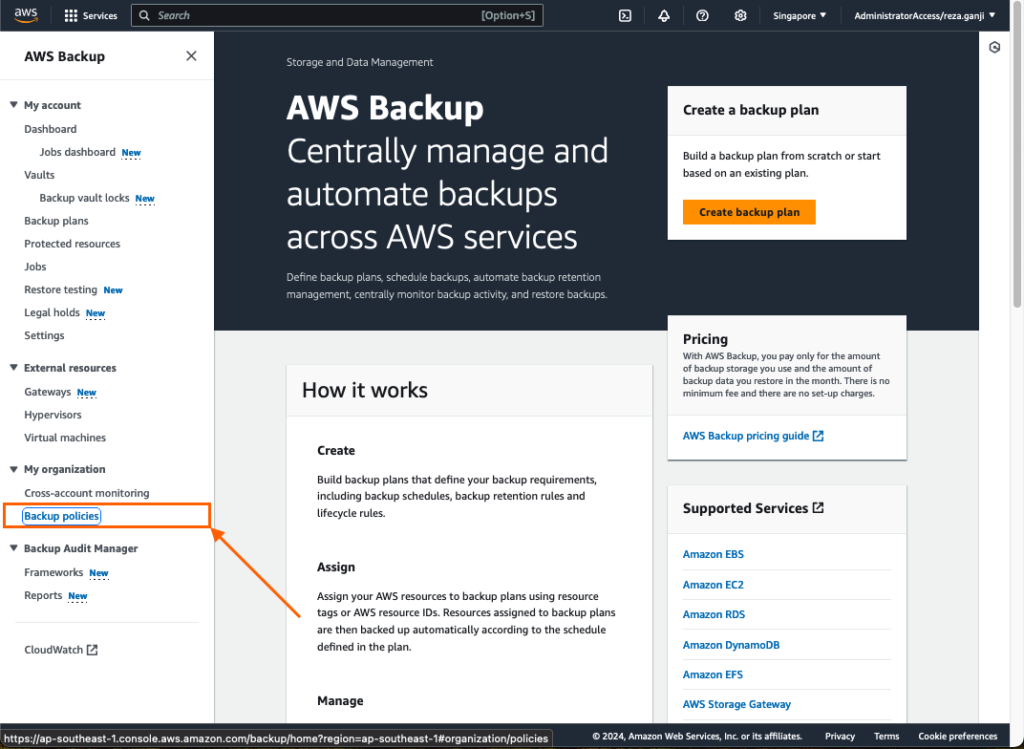
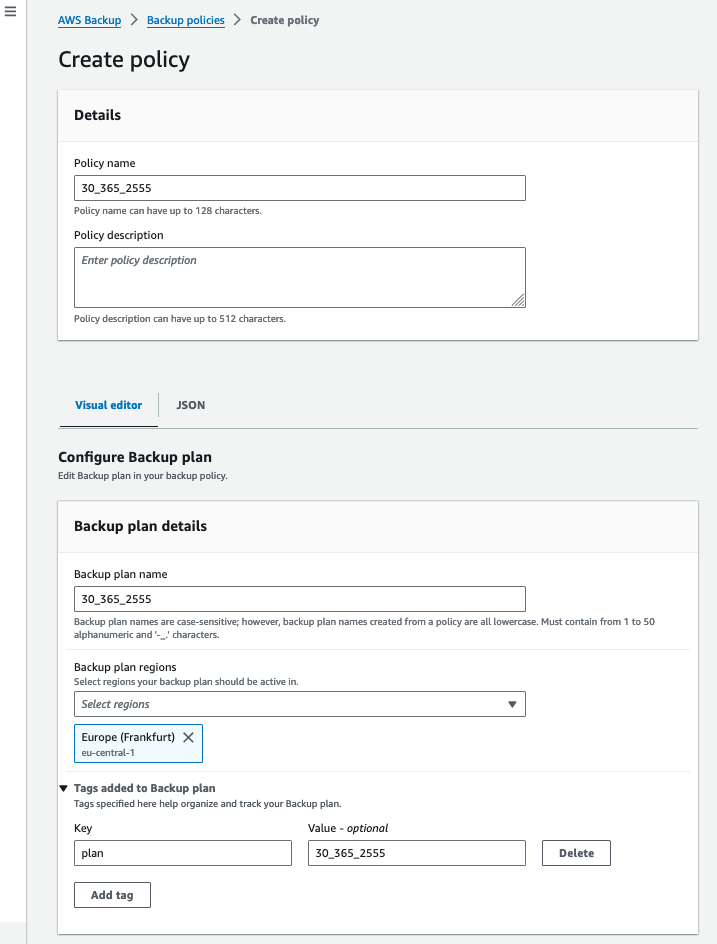
Click on Backup policies from the AWS Backup console under the “My Organization” section, then click “Create backup policy.” I will create two similar backup policies except for the retention period:
30_365_2555
30_365_3652
You might wonder how many backup policies you would need to create if you have many cases in your organization due to different retentions per resource or the data the resource contains. Suppose you require many policies due to retention requirements, as explained previously, then using infrastructure as code is a must, and a Terraform object and a loop would create policies for you with a single resource.
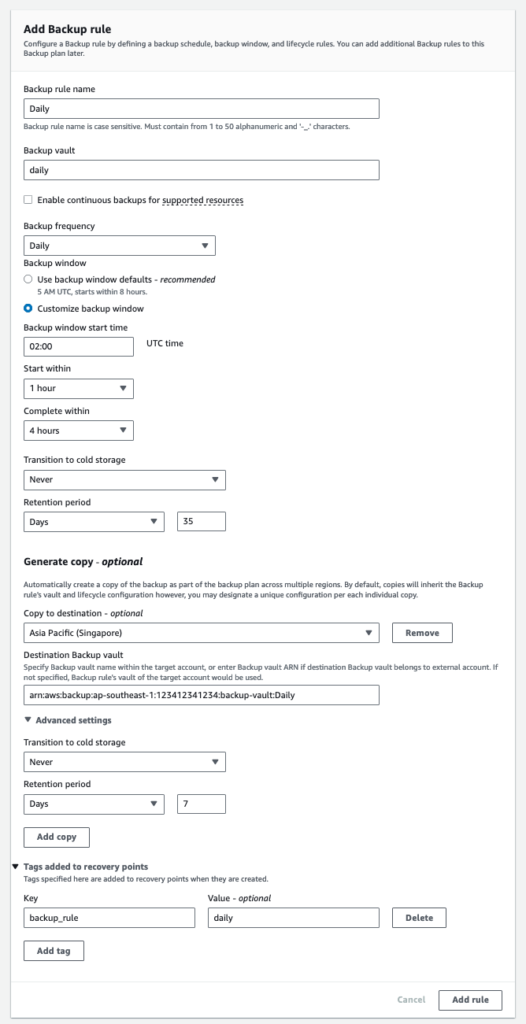
In the screenshots you can see that my backup policy and plan within the policy is named after the retention tag structure that I have created. Followed by, the backup rule which retains the daily backups for 35 days and replicates a copy of the recovery points into another vault in a different region or account.
IMPORTANT: as of now, AWS Backup does not support the replication/copy of recovery points in cross-region AND cross-account. You must decide which one is more important.
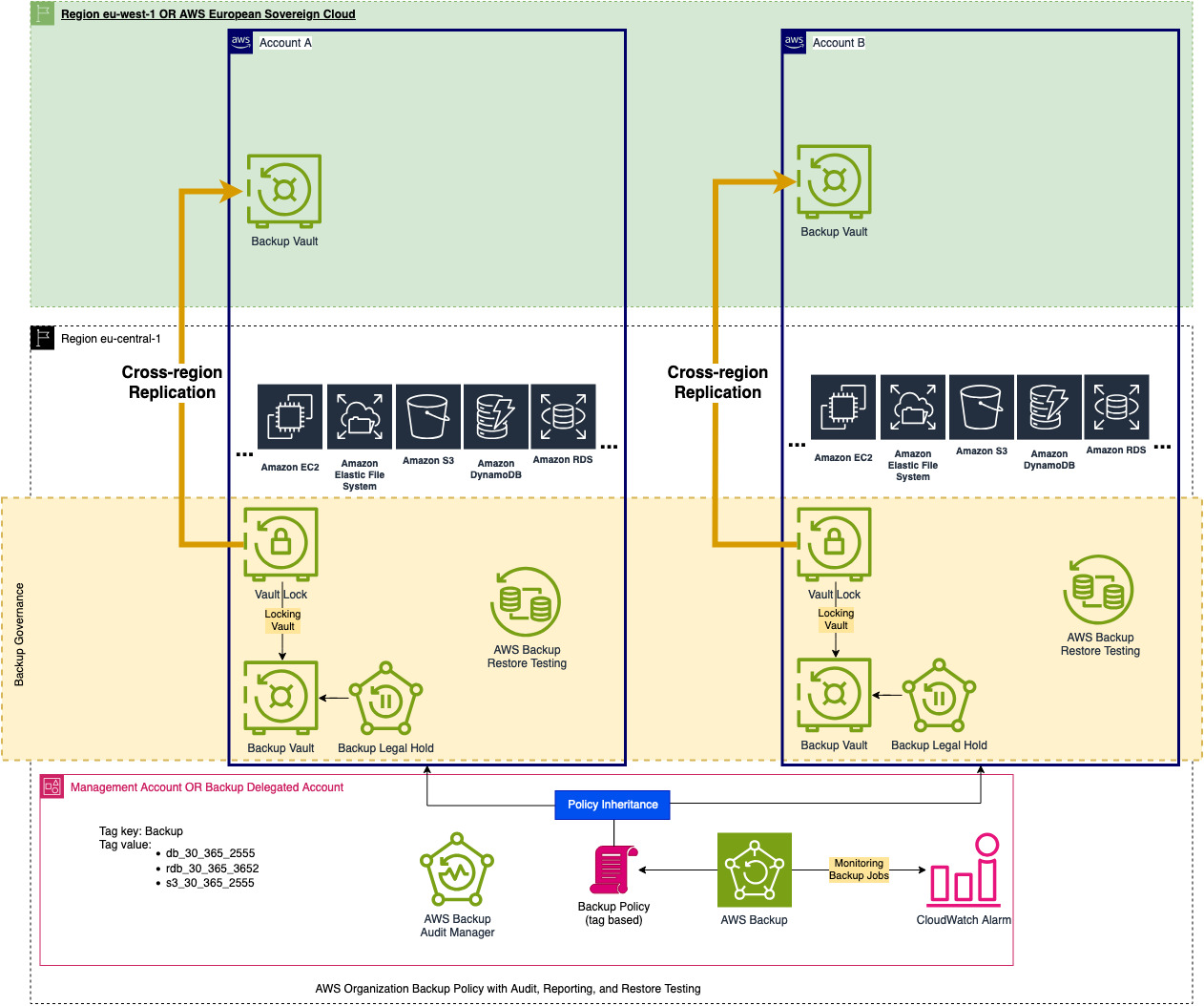
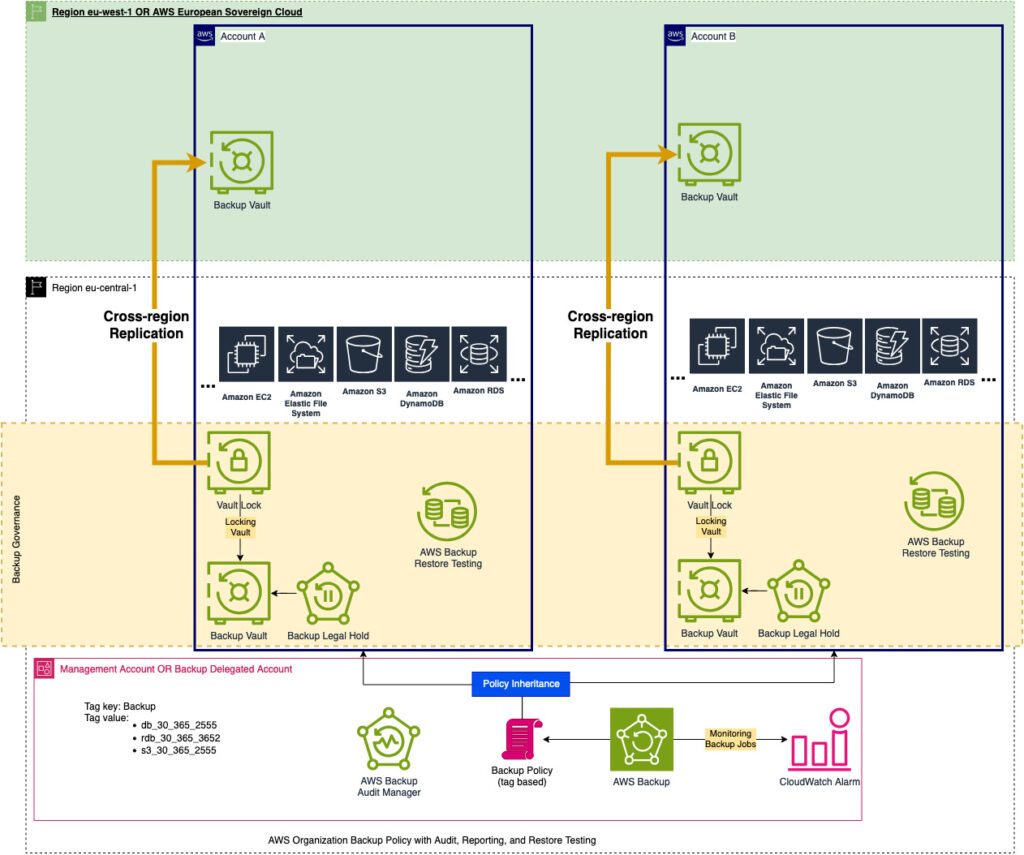
In the architecture diagram, which I will reshare at the bottom of the article, you can see that the replication plan is to implement eu-west-1 or Sovereign Cloud. AWS European Sovereign Cloud is a new isolated region that is being launched next year and is meant to be used for highly regulated entities and governments within Europe. You can read more about it here: https://aws.amazon.com/compliance/europe-digital-sovereignty/
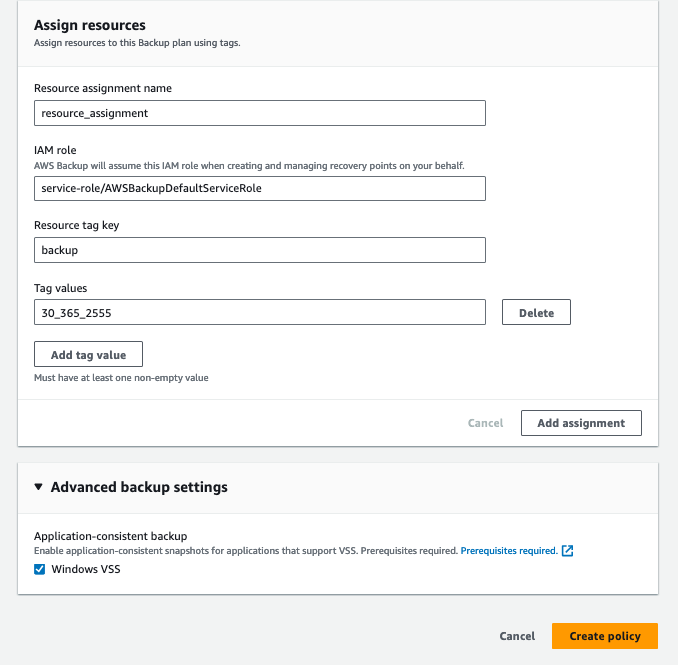
In the resource assignment section, I choose the default service role and use the backup key of “backup” with the value “30_365_2555”.
With this policy created, I can now back up all resources across my AWS Organization that are tagged with the proper tag key and value and are attached to the backup policy. Simple!
Continuous Backup
AWS Backup supports a feature called Continuous Backup. It provides point-in-time recovery (PITR) for Aurora, RDS, S3, and SAP HANA on Amazon EC2 resources. Continuous Backup continuously tracks changes to the resources and enables the ability to restore them to any specific second within a defined retention period. This significantly reduces data loss (close to none) during an incident.
A few important points to remember:
Continuous backup is generally safer because it captures data changes continuously and allows for recovery at any specific point in time, offering better protection against data loss between scheduled snapshots.
Snapshot backups are typically faster to recover because they represent a complete, point-in-time state of the resource, so there’s no need to reconstruct incremental changes.
Continuous backups are limited to 35 days.
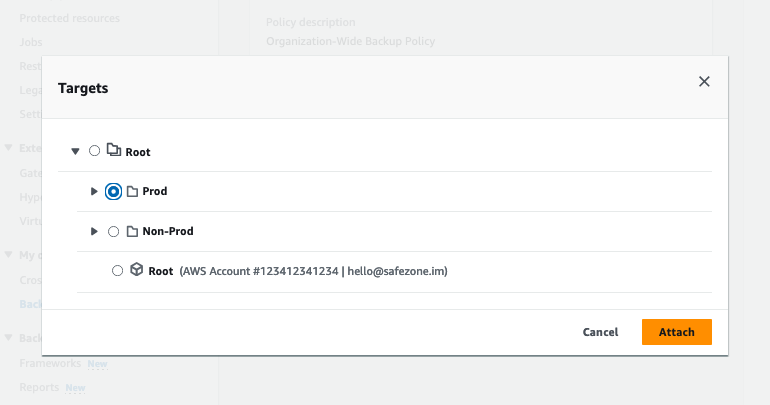
Policy Attachment
AWS Backup Policy Attachment allows us to assign the backup plans to resources running across the AWS Organization OUs or Accounts. By attaching the backup policy to an OU within the organization called “Prod”, all my resources are not being backed up.
In this part, we have created the vaults, vault lock, and backup policy and finally attached the policy to specific OU targets.
As a reminder, here is what the target architecture diagram looks like:
In the next part, I will elaborate on AWS Backup Legal Holds, Audit Manager,
I was asked to provide a testimonial for CloudWatch due to the level of usage and the way it was architected and used in the organization, and here is where you can see my words:
In Part 1, I emphasized DORA’s requirements and the overall architecture of resource backup within an organization. In this part, I will focus on backup initiation strategies, vaults, retention of the recovery points, and tagging policy.
Backup Strategies
If the resources in your AWS Organization are managed via code, aka infrastructure as code, you are on good terms. Otherwise, you will need to spend some time categorizing and structuring your resources based on their type and data retention.
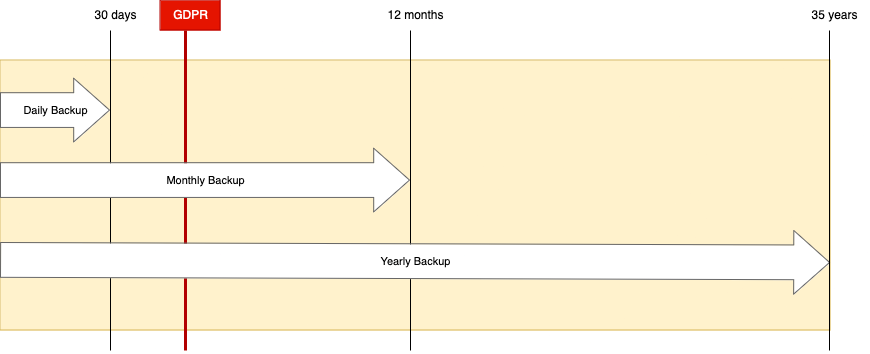
First, let’s define the retention of the resources and its data based on the legal requirements. For example, as a financial entity, you must retain specific data about the customer or its transactions for between 7 and 35 years! This would mean the data deletion process, which is also a GDPR requirement, must be in alignment with the data backup process; otherwise, you will end up retaining backups that do not contain all the customer data that is legally needed.
To make the GDPR relation with a backup more understandable, look at the timeline below:
Now, let’s review the process:
You take daily, monthly, and yearly backups. Daily recovery points are retained for 30 days, monthly for 12 months, and yearly for 35 years.
Every team has a pre-defined process for triggering the data deletion from a notification received from an event bus every 35 days.
The customer’s personally identifiable data gets deleted, and you have the customer data in the database only for another 30 days since the daily backup recovery points are the only item containing the customer data.
What I mentioned above as an example scenario is a highly misaligned plan of action in a financial institution, but it can happen! To stay compliant and retain the data, nullifying the customer’s PII data is always easier than deleting it. Retaining the customer data in warm storage of the production database without needing it is not exactly ideal. Still, if you do not have a properly structured data warehouse that complies with the regulatory requirements and builds for compliance needs, then you do not have much of a choice.
Now that you understand the relationship between GDPR data deletion and backups and how you should consider it, we will move on to the backup policy.
In my view, AWS Backup is one of the best solutions AWS has released in the storage category for compliance and operation. You can operate AWS Backup well within the root account or delegate an administrator to a dedicated backup account to limit the root account usage and exposure for best practices. The architecture diagram I provide would work perfectly with either of them.
The goal is to create a backup policy that controls the resources deployed in any AWS organization account. A backup policy based on a legal requirement will likely be set to back up resources across multiple AWS accounts. Thus, numerous backup policies with different sets of rules are needed to satisfy the legal and compliance needs.
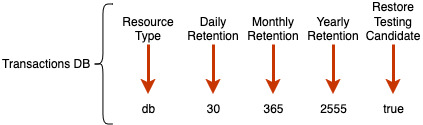
In this scenario, let’s assume we only need to create two backup policies: one with seven years of yearly retention (let’s call it transactions db) and another with ten years (rewards db). Both the daily and monthly backup policies are identical.
daily
monthly
yearly
transactions db
30
365
2555
rewards db
30
365
3652
DB retentions in days
AWS Backup policy that is a part of the Organization policy only supports tagging. This means a tag-based policy is your best friend for implementing backups cross-account.
daily
monthly
yearly
tag
transactions db
30
365
2555
db_30_365_2555
rewards db
30
365
3652
db_30_365_3652
DB retentions in days
If you look at the image above, you see that the restore testing candidate is true, but it is not part of the tag. That is because a separate tag key and value will be used for automated restore testing, which is also a DORA requirement.
Backup Vaults
There are three retention categories defined in the backup strategy daily, monthly, and yearly.
What is AWS Backup Vault?
AWS Backup Vaults are secure storage containers (virtually) within the AWS Backup service, designed to store backup copies of AWS resources such as Amazon EC2 instances, Amazon RDS databases, Amazon EBS volumes, and more. Vault provides a centralized, organized location for managing and protecting the recovery points.
Key Features of AWS Backup Vaults:
Secure Storage:
Backup vaults offer encryption for backups at rest using AWS Key Management Service (KMS) encryption keys. You can specify a KMS key to encrypt your backups for added security.
Centralized Management:
Backup vaults help in managing backups from various AWS services in a centralized place, simplifying the backup management process across multiple AWS accounts and regions.
Cross-Region and Cross-Account Backups:
AWS Backup allows you to create backup copies in different regions (cross-region backups) and share them across different AWS accounts (cross-account backups) for improved resilience against regional failures and data loss.
Access Control:
Backup vaults are integrated with AWS Identity and Access Management (IAM), allowing you to control who can access and manage backups stored in the vault. You can define detailed policies for who can create, restore, or delete backups.
Retention and Lifecycle Policies:
You can define retention policies for backups stored in the vault, specifying how long backups should be retained before they are automatically deleted. This helps in compliance with data retention regulations like DORA.
Monitoring and Audit:
AWS Backup integrates with AWS CloudTrail, providing detailed logs of backup operations such as creation, deletion, and restoration of backups. This enables auditing and tracking of all backup activities.
Immutable Backups:
AWS Backup Vault Lock is a feature that allows you to make backups immutable, meaning they cannot be deleted or altered for a specified period, which helps in protecting against accidental or malicious data loss (useful for compliance with regulations).
As a reminder, here is what the target architecture diagram looks like:
In the next part, I will elaborate on the backup policy creation, legal hold, and vault lock.
When discussing cloud resource backup and restoration, there are many ways to handle them. You may wonder what the best way is! Should you use backup and restoration software that you might be already familiar with from your on-premises data center, like Vaeem? Or should you consider using software built in the age of cloud-native solutions?
You will find the answers to those questions in this post. I tried to simplify the selection process based on organizational needs. If you must comply with DORA, this is the right stop for you. If you do not have to comply with DORA and you still want to take control of your backups in a comprehensive manner, then you are doing the right thing, as anything can happen at any time, especially with ever-changing resources running on the cloud.
The Digital Operational Resilience Act (DORA) outlines specific requirements for financial entities regarding the resilience of their ICT systems, including clear mandates for resource backup, backup testing, restoration, auditing, and retention. Here is a summary of the exact DORA requirements related to these aspects, along with references to their respective clauses, I will then explain how to meet each of these requirements:
1. Backup Requirements
Regular backups: Financial institutions must ensure regular backups of critical data and ICT resources. Backups should be done frequently and stored in secure locations. Reference: Article 11, paragraph 1(b).
Data availability: Backup systems should ensure that critical data and systems remain available, even in cases of severe operational disruptions. Reference: Article 11, paragraph 2.
2. Backup Testing
Regular testing of backups: Backups should be tested periodically to ensure that the data can be recovered effectively. This includes testing for data integrity, recovery procedures, and accessibility of critical systems during potential incidents. Reference: Article 11, paragraph 1(e).
Simulated disaster recovery: Financial entities must simulate disaster recovery scenarios to ensure that they can recover critical functions and data within the required timeframes. Reference: Article 11, paragraph 4.
3. Restoration Requirements
Timely restoration: Procedures for restoring critical data and ICT systems must be in place to ensure operational continuity within predefined recovery time objectives (RTOs). Reference: Article 11, paragraph 1(d).
Recovery point objectives (RPOs): Institutions should set and maintain appropriate recovery point objectives to minimize data loss during recovery. Reference: Article 11, paragraph 2(b).
4. Audit Requirements
Audit trail: Financial institutions must maintain a comprehensive and secure audit trail of backup processes, testing procedures, and restoration activities to ensure traceability and accountability. Reference: Article 16, paragraph 1.
Third-party audits: For outsourced backup or recovery services, financial entities must ensure that third-party providers also comply with audit requirements and that their performance is regularly reviewed. Reference: Article 28, paragraph 4.
5. Retention Requirements
Retention policies: Financial institutions must establish clear data retention policies for backup data, aligned with legal and regulatory obligations. These policies should ensure that data is retained for a period long enough to address operational and legal requirements, while also considering data minimization principles. Reference: Article 11, paragraph 1(c).
Data deletion: Procedures must be in place to securely delete or dispose of backup data once the retention period has expired, in compliance with data protection laws (such as GDPR). Reference: Article 11, paragraph 5.
6. Backup Security
Access control: Backups must be protected by strong access control measures to prevent unauthorized access, alteration, or deletion. This includes encryption of backup data both in transit and at rest. Reference: Article 11, paragraph 1(e).
Physical security: If backups are stored off-site or in a separate physical location, financial entities must ensure that these locations are secure and comply with applicable security requirements. Reference: Article 11, paragraph 1(b).
7. Redundancy and Geographical Distribution
Geographically diverse backup locations: Backups should be stored in geographically diverse locations to ensure that natural disasters or regional disruptions do not affect the ability to recover critical data. Reference: Article 11, paragraph 1(b).
Redundant backup infrastructure: Institutions should maintain redundant backup systems to ensure continuous availability even if the primary backup system fails. Reference: Article 11, paragraph 1(e).
8. Backup and Disaster Recovery Plan Integration
Integration with disaster recovery plans: Backups must be integrated into the broader disaster recovery and business continuity plans. This includes ensuring backup procedures and recovery times align with overall incident response and resilience strategies. Reference: Article 11, paragraph 1(d).
9. Outsourcing Backup Services
Oversight of third-party providers: If backups are outsourced to third-party service providers (e.g., cloud providers), financial entities must ensure that the provider adheres to the same DORA requirements and regularly assess the provider’s performance, including backup reliability and security. Reference: Article 28, paragraph 2.
10. Backup Documentation
Documented backup processes: Institutions are required to document their backup strategies, including frequency, testing schedules, and recovery procedures. Documentation should be kept up to date and accessible to relevant personnel. Reference: Article 11, paragraph 1(f).
11. Incident Notification
Reporting backup failures: Any incident in which backup or recovery processes fail must be reported to the appropriate authorities as part of DORA’s incident reporting requirements. Reference: Article 19, paragraph 1.
12. Continuous Monitoring and Improvement
Continuous monitoring of backup systems: Financial entities must continuously monitor the effectiveness of their backup systems and adjust processes to address evolving risks or operational changes. Reference: Article 12, paragraph 1.
First things first, I am assuming a few things that I will list down here:
Multiple AWS accounts are running in a multi-account architecture
All resources must be backed up
You have control over all the resources that need to be backed up
You know the data that is stored in the databases well and its legal retention requirement
Based on the requirements of DORA together with the assumption on how your infrastructure would look like, let’s draw a visual for better understanding:
In the next parts I will explain how to implement each of the components that are in the diagram above and how to meet the DORA requirements.
Developing and Implementing Large-Scale DevSecOps Solutions
The development and implementation of large-scale DevSecOps solutions is a multifaceted process that demands a comprehensive approach. Integrating security into every phase of the development and operations lifecycle is paramount. This integration ensures that security measures are not merely an afterthought but a fundamental component of the entire process. Leveraging both business and technical acumen is crucial to address complex issues effectively and generate innovative solutions.
A key methodology in developing robust DevSecOps solutions involves the adoption of a shift-left security approach. By embedding security practices early in the development process, potential vulnerabilities can be identified and mitigated before they evolve into significant threats. Continuous integration and continuous delivery (CI/CD) pipelines play a central role in this strategy, enabling automated security testing at every stage of the software development lifecycle.
Several tools and frameworks are instrumental in ensuring the seamless integration of security into DevOps practices. Tools such as Jenkins, GitLab CI, and CircleCI facilitate automated testing and deployment, while security-specific tools like OWASP ZAP, Snyk, and Aqua Security provide continuous monitoring and vulnerability assessment. These tools not only streamline processes but also enhance the overall security posture of the application.
Effective large-scale DevSecOps implementation also relies on strategic frameworks like the National Institute of Standards and Technology (NIST) Cybersecurity Framework and the DevSecOps Foundation. These frameworks provide structured guidelines and best practices that help organizations navigate the complexities of integrating security into their DevOps practices.
Case studies offer valuable insights into successful implementations. For example, a leading financial institution implemented a comprehensive DevSecOps strategy that reduced their vulnerability remediation time by 50%. By leveraging automated security tools and integrating security practices into their CI/CD pipeline, the institution not only enhanced their security measures but also achieved significant operational efficiencies.
Another notable example is a global e-commerce giant that adopted a DevSecOps approach to manage its extensive software infrastructure. The integration of security into their development process resulted in a 40% reduction in security incidents, demonstrating the efficacy of a well-implemented DevSecOps strategy.
In conclusion, developing and implementing large-scale DevSecOps solutions requires a strategic blend of methodologies, tools, and frameworks. By prioritizing security integration, leveraging automation, and adhering to established best practices, organizations can effectively address complex security challenges and achieve substantial benefits in both security posture and operational efficiency.
Strategic Initiatives and Stakeholder Management
Strategic initiatives play a pivotal role in the successful implementation of DevSecOps within large-scale solutions. Proactive participation in critical decision-making processes, coupled with a strategic mindset, is fundamental to driving competitive advantage. A well-defined strategy enables organizations to anticipate challenges, allocate resources efficiently, and align DevSecOps practices with broader business goals, thus ensuring that security and development processes are in synergy.
One of the key aspects of strategic initiatives in DevSecOps is the cultivation of excellent stakeholder relationships. Meeting the needs and expectations of stakeholders, including developers, security professionals, and business executives, is essential for the smooth execution of DevSecOps projects. Effective stakeholder management requires a thorough understanding of their priorities and concerns, enabling the development of solutions that address these aspects comprehensively. Regular communication, transparency, and active engagement are critical in building trust and ensuring alignment across the organization.
Ensuring compliance with regulatory requirements is another crucial element of strategic initiatives. Organizations must stay abreast of evolving regulations and standards to avoid potential legal repercussions and maintain their reputation. Integrating compliance measures into the DevSecOps pipeline ensures that security and quality are not compromised, and helps in fostering a culture of continuous improvement and adherence to industry best practices.
Techniques for effective stakeholder engagement include regular meetings, feedback loops, and collaborative platforms that facilitate open communication. Cross-functional teams should be encouraged to share insights and work collectively towards common goals. Workshops, training sessions, and collaborative tools can enhance understanding and cooperation among different teams, thereby driving the success of DevSecOps projects.
In conclusion, strategic initiatives and robust stakeholder management are indispensable for the successful execution of DevSecOps projects. By fostering collaboration, ensuring compliance, and aligning with business objectives, organizations can achieve sustained growth and a competitive edge in the market.
Leveraging Business and Technical Acumen for Large-Scale DevSecOps Solutions
In the realm of large-scale DevSecOps solutions, a profound understanding of both business and technical facets is paramount. This dual expertise is not merely beneficial but essential for developing and implementing solutions that are both robust and scalable. A comprehensive approach that synthesizes business objectives with technical capabilities ensures that the solutions not only address immediate security concerns but also align seamlessly with long-term organizational goals.
For instance, consider the deployment of a large-scale DevSecOps framework within a multinational corporation. The technical team might focus on integrating advanced security protocols and automating compliance checks throughout the development lifecycle. Meanwhile, the business team would ensure that these technical measures support broader organizational strategies, such as market expansion or regulatory adherence. By leveraging insights from both domains, the corporation can create a cohesive, resilient DevSecOps environment that mitigates risks while facilitating growth.
Furthermore, proactive engagement with cross-functional teams is instrumental in driving competitive advantage. When business analysts, security experts, developers, and operations personnel collaborate from the outset, they can identify potential issues and opportunities early in the process. This interdisciplinary collaboration fosters a culture of continuous improvement and innovation, where every team member is aligned towards a common goal. It also enables the organization to respond swiftly to emerging threats and adapt to evolving market demands.
Examples of successful large-scale DevSecOps implementations often highlight the importance of this integrated approach. Companies that excel in this domain typically adopt a strategic mindset, viewing security not as a standalone function but as an integral component of their business strategy. They invest in training and development to equip their teams with the necessary skills and knowledge, thereby ensuring that both business and technical perspectives are equally represented in decision-making processes.
In conclusion, leveraging business and technical acumen is crucial for the successful deployment of large-scale DevSecOps solutions. By adopting a holistic approach and fostering cross-functional collaboration, organizations can develop solutions that are not only secure and efficient but also aligned with their overarching business objectives. This strategic integration is key to achieving a sustainable competitive advantage in today’s complex digital landscape.
Strategic Stakeholder Management and Compliance in DevSecOps
In the realm of DevSecOps, effective stakeholder management is paramount to the success of any project. Cultivating strong relationships with stakeholders ensures that their needs and expectations are met throughout the project lifecycle. This involves establishing clear lines of communication, managing expectations meticulously, and addressing potential issues proactively.
Effective communication is the cornerstone of stakeholder management. Regular updates and transparent reporting help maintain trust and keep stakeholders informed about the project’s progress. Utilizing various communication channels, such as regular meetings, emails, and project management tools, can facilitate seamless information flow. Setting clear objectives and timelines from the outset also helps in aligning stakeholder expectations with the project’s capabilities and constraints.
Expectation management in DevSecOps requires a nuanced approach. Stakeholders often have varying levels of technical knowledge and different priorities. It’s essential to tailor communication strategies to address these differences, ensuring that each stakeholder understands how the project aligns with their interests. This can be achieved through personalized briefings, detailed documentation, and interactive demonstrations of project milestones.
Proactive problem-solving is another critical aspect of stakeholder management. Identifying potential issues before they escalate and developing mitigation strategies can prevent disruptions. Regular risk assessments and contingency planning are vital practices in this regard. Engaging stakeholders in these processes also fosters a collaborative environment, where their insights and feedback can contribute to more robust solutions.
Compliance with regulatory requirements is a crucial component of DevSecOps expertise. Staying abreast of the latest regulations and ensuring that all processes and practices adhere to these standards can assure business owners of exceptional service and resource management. This involves regular audits, comprehensive documentation, and continuous monitoring for compliance.
Examples of successful stakeholder management and compliance strategies include implementing automated compliance checks and fostering a culture of transparency and accountability. For instance, using continuous integration and continuous deployment (CI/CD) pipelines that incorporate security checks ensures that compliance issues are identified and resolved promptly. Additionally, fostering an open dialogue with stakeholders about compliance measures and their importance can enhance trust and collaboration.
By integrating strategic stakeholder management and rigorous compliance practices, organizations can navigate the complexities of DevSecOps more effectively, ensuring that both stakeholder satisfaction and regulatory standards are consistently met.
Developing and Implementing Large-Scale DevSecOps Solutions
Developing and implementing large-scale DevSecOps solutions requires a meticulous approach, emphasizing the integration of security practices within the DevOps framework to ensure a robust and secure software development lifecycle. The cornerstone of this integration lies in embedding security directly into the continuous integration and continuous deployment (CI/CD) pipelines, ensuring that security is not an afterthought but a fundamental component of the development process.
One of the pivotal methodologies in DevSecOps is Infrastructure as Code (IaC), which allows for the automated management and provisioning of technology infrastructure through machine-readable configuration files. By treating infrastructure the same way as application code, organizations can apply the same rigor of version control, testing, and deployment, ensuring consistency and minimizing human error. This approach is particularly beneficial in large-scale environments where manual configuration can be both error-prone and inefficient.
Automated security testing is another critical element of DevSecOps. Tools such as static application security testing (SAST) and dynamic application security testing (DAST) are integrated into the CI/CD pipeline to continuously monitor and evaluate the code for vulnerabilities. These tools enable early detection of security issues, allowing developers to address them before they can be exploited in a production environment. Additionally, runtime application self-protection (RASP) can provide real-time monitoring and protection, further enhancing the security posture of applications.
Scaling these practices to accommodate large, complex systems involves a combination of technical acumen and strategic planning. Developers and security professionals must collaborate closely to identify potential vulnerabilities and devise strategies to mitigate them. This collaboration is facilitated by leveraging both business and technical skills to align security objectives with organizational goals, ensuring that security measures support, rather than hinder, business operations.
In essence, the successful adoption of DevSecOps practices in large-scale environments hinges on the seamless integration of security into every phase of the development lifecycle. By utilizing methodologies such as CI/CD, IaC, and automated security testing, organizations can create a resilient and scalable framework that not only enhances security but also drives efficiency and innovation in software development.
Strategic Initiatives and Stakeholder Management in DevSecOps
In the realm of DevSecOps, strategic initiatives form the backbone of successful implementation and operational efficiency. Championing these initiatives not only drives effective results but also grants organizations a competitive edge. By proactively collaborating with cross-functional teams—comprising developers, operations, and security professionals—organizations can drive strategic decisions that foster a culture of continuous improvement.
Effective stakeholder management is paramount in DevSecOps. Building and maintaining robust relationships with stakeholders is essential to comprehending their needs and expectations. This ensures that technical requirements are balanced with business goals, and that compliance with regulatory requirements is achieved. For instance, when integrating security practices into the development pipeline, it is crucial to engage with stakeholders to ensure that these practices do not impede the delivery timelines or impact the user experience negatively.
Proactive collaboration within cross-functional teams also entails regular communication and feedback loops. This enables the identification of potential bottlenecks and the implementation of timely solutions. For example, a security team might identify a vulnerability during the development phase. By working closely with the developers, they can promptly address the issue without causing significant delays.
Moreover, a strategic mindset is vital in navigating the complexities of large-scale DevSecOps projects. This involves anticipating risks, setting clear objectives, and aligning resources to meet these objectives. The ability to foresee and adapt to changing objectives and technological advancements is essential for sustaining momentum and achieving long-term success. An example of this could be the adoption of new security protocols in response to emerging threats, which requires both strategic foresight and agile execution.
Ultimately, the integration of strategic initiatives and effective stakeholder management ensures that DevSecOps solutions are not only technically sound but also aligned with business objectives. This holistic approach paves the way for innovation, resilience, and sustained competitive advantage in the ever-evolving landscape of technology and security.
Expertise in DevSecOps is instrumental in spearheading strategic initiatives that align technical solutions with overarching business objectives. By leveraging a deep understanding of DevSecOps principles, one can effectively identify and implement strategies that drive impactful results. The alignment of DevSecOps with business goals ensures that technological advancements contribute directly to the company’s success, optimizing both operational efficiency and innovation capacity.
One of the critical aspects of championing DevSecOps initiatives is the ability to foresee and address complex technical challenges. For instance, in a recent project, we encountered substantial security vulnerabilities during the integration phase of a new software deployment. Through a thorough risk assessment and implementation of advanced security protocols, we mitigated potential threats and enhanced the overall security posture of the enterprise. This proactive approach not only safeguarded sensitive data but also reinforced stakeholder confidence in the system’s reliability.
Furthermore, my role in critical decision-making processes often involves close collaboration with cross-functional teams. By fostering a culture of open communication and shared objectives, we ensure that every strategic initiative is comprehensively evaluated from multiple perspectives. This collaborative effort is crucial in developing innovative solutions that are both technically sound and aligned with business strategies. For example, when implementing a continuous integration/continuous deployment (CI/CD) pipeline, engaging with development, operations, and security teams allowed us to streamline the process while maintaining rigorous security standards and operational efficiency.
In addition, my technical acumen plays a pivotal role in identifying the potential for automation and optimization within the DevSecOps framework. By automating repetitive tasks and integrating advanced monitoring tools, we can significantly reduce the time-to-market for new features, thereby providing a competitive edge in the fast-paced business environment. This proactive approach not only enhances productivity but also ensures a robust and secure development lifecycle.
Ultimately, my expertise in DevSecOps enables me to lead strategic initiatives that drive business success. By aligning technical solutions with business objectives and fostering collaborative decision-making, we can address complex challenges and develop innovative, effective strategies that propel the organization forward.
Cultivating Stakeholder Relationships and Ensuring Compliance
Building and maintaining robust relationships with stakeholders is fundamental to the success of any DevSecOps initiative. Our approach is centered on understanding and aligning with stakeholder needs and expectations from the outset. To achieve this, we employ a multi-faceted strategy that includes regular communication, transparent reporting, and active collaboration. By engaging stakeholders early and consistently throughout the project lifecycle, we ensure that their concerns and requirements are continuously addressed.
One of our primary strategies involves conducting thorough stakeholder analysis to identify key individuals and groups, understanding their roles, and pinpointing their unique needs. We then tailor our engagement efforts, ensuring that each stakeholder is kept informed and involved at appropriate levels. This approach not only fosters trust and cooperation but also aids in preempting potential issues before they escalate.
Ensuring compliance with regulatory requirements is another critical component of our DevSecOps practices. We leverage our extensive experience to navigate the complex landscape of industry regulations and standards. By integrating compliance checks into our continuous integration and continuous deployment (CI/CD) pipelines, we ensure that each iteration of the software meets the necessary compliance criteria. This proactive method prevents costly delays and rework, ultimately driving successful project outcomes.
Moreover, we provide business owners with comprehensive resources and support to help them stay abreast of evolving regulatory landscapes. These resources include training programs, compliance checklists, and regular updates on regulatory changes. By equipping business owners with the knowledge and tools they need, we enable them to adapt swiftly to new regulations and maintain compliance without compromising on their business objectives.
An example of our commitment to stakeholder relationships and compliance can be seen in a recent project where we worked with a financial services company. By maintaining open lines of communication and providing ongoing compliance support, we not only met the stringent regulatory requirements but also delivered a secure and efficient solution that aligned with the company’s business goals. This holistic approach underscores our ability to deliver exceptional service and drive successful outcomes in any DevSecOps endeavor.
Leveraging Technical and Business Acumen for Effective DevSecOps Solutions
Developing and implementing large-scale DevSecOps solutions requires a blend of both technical expertise and business acumen. By integrating security into the development process, I ensure that applications are not only robust but also secure. My approach involves utilizing a variety of methodologies and tools to embed security measures from the outset, mitigating risks and enhancing the overall quality of the software.
One methodology I employ is the Continuous Integration/Continuous Deployment (CI/CD) pipeline, which automates the integration and deployment of code changes. By integrating security checks at each stage of the pipeline, I can identify vulnerabilities early and address them before they escalate into significant issues. Tools like static code analyzers, dynamic application security testing (DAST), and dependency checkers are instrumental in this process, allowing for a comprehensive security assessment.
My business knowledge plays a crucial role in aligning these technical strategies with organizational objectives. For instance, understanding the business impact of a security breach enables me to prioritize security measures that safeguard critical assets. A notable example is when I resolved a complex issue involving a legacy system with numerous vulnerabilities. By developing a custom middleware solution, I was able to bridge the gap between the old and new systems, ensuring seamless integration and enhanced security.
Moreover, my ability to translate business needs into technical strategies is evident in my role in championing strategic initiatives. I proactively collaborate with cross-functional teams, including developers, operations, and security experts, to foster a culture of security awareness and shared responsibility. This collaborative approach not only enhances the effectiveness of DevSecOps solutions but also drives competitive advantage by enabling faster, more secure releases.
In summary, leveraging both technical and business acumen is essential for the successful implementation of large-scale DevSecOps solutions. By integrating security into every phase of the development lifecycle and aligning technical strategies with business goals, I ensure the delivery of robust, secure, and competitive applications.
Building Strong Stakeholder Relationships and Ensuring Compliance
In the realm of large-scale DevSecOps solutions, establishing and nurturing robust stakeholder relationships is pivotal to driving success. My strategic approach centers on understanding and aligning with stakeholders’ needs and expectations at every phase of the project lifecycle. This begins with initial consultations where I actively listen and gather insights to tailor my services to their unique objectives. Through continuous communication and transparent reporting, I ensure that stakeholders remain informed and engaged, fostering a collaborative environment conducive to achieving the project’s goals.
To meet and exceed stakeholder expectations, I deploy a range of methodologies designed to optimize both service delivery and resource allocation. Regular feedback loops and iterative development cycles are integral, allowing for adjustments and improvements in real-time. This agile approach not only enhances the quality of the deliverables but also instills confidence among stakeholders, affirming their trust in my expertise.
Ensuring compliance with regulatory requirements is another cornerstone of my practice. I implement comprehensive processes and stringent checks to uphold the highest standards of security and governance in DevSecOps practices. This includes conducting thorough risk assessments, regular audits, and adopting industry best practices for data protection and privacy. My commitment to compliance is unwavering, and I leverage my in-depth knowledge of regulatory frameworks to navigate complex landscapes effectively.
A notable example of my effective stakeholder engagement and compliance achievement can be seen in a recent project with a financial services firm. By prioritizing open dialogue and adapting to their specific needs, I successfully aligned the DevSecOps strategy with their stringent regulatory requirements. Through meticulous planning and execution, the project not only met compliance standards but also significantly enhanced the firm’s operational security, demonstrating the tangible benefits of my approach.
In summary, the synthesis of strong stakeholder relationships and rigorous compliance practices is essential for the successful deployment of large-scale DevSecOps solutions. My dedication to these principles ensures that business owners can confidently rely on my expertise to meet their objectives while maintaining the highest standards of security and governance.
Mastering DevSecOps: Leveraging Business and Technical Acumen
Developing and implementing large-scale DevSecOps solutions demands a harmonious blend of business acumen and technical expertise. The primary goal is to integrate security seamlessly into the DevOps process, ensuring that security considerations are embedded throughout the development lifecycle. This holistic approach to security mitigates potential vulnerabilities early in the development phase, reducing risks and enhancing the overall resilience of the software.
One of the critical aspects of successful DevSecOps implementation is the ability to combine business knowledge with technical skills. This dual approach enables the identification of complex issues and the generation of innovative solutions that are both technically sound and aligned with business objectives. For instance, understanding the business impact of security breaches allows for prioritizing security measures that protect critical assets while maintaining operational efficiency.
Strategic initiatives play a pivotal role in delivering effective DevSecOps solutions. These initiatives often involve the adoption of advanced security tools, the establishment of robust security protocols, and the continuous monitoring of the development environment. By leveraging these strategies, organizations can achieve a higher level of security compliance and operational excellence. Examples of successful implementations include automated security testing, which integrates security checks into the CI/CD pipeline, and the deployment of security information and event management (SIEM) systems for real-time threat detection and response.
Proactive collaboration with cross-functional teams is essential for driving competitive advantage in DevSecOps. This collaboration ensures that all stakeholders, from developers to security analysts, are aligned and working towards a common goal. Methodologies such as Agile and Scrum facilitate this integration by promoting continuous communication and iterative progress. Tools like Jira and Confluence support these methodologies by providing platforms for tracking progress and sharing knowledge, ensuring that security is a shared responsibility across the organization.
In conclusion, mastering DevSecOps involves a meticulous balance of business insight and technical prowess. Through strategic initiatives and collaborative efforts, organizations can build secure, resilient software systems that meet both business objectives and security standards, ultimately driving success in a competitive landscape.
Building Stakeholder Relationships: Meeting Needs and Ensuring Compliance
In the realm of large-scale DevSecOps solutions, the importance of fostering robust stakeholder relationships cannot be overstated. Engaging stakeholders effectively is paramount to ensuring their needs and expectations are met, while simultaneously adhering to stringent regulatory standards. The commitment to cultivating these relationships begins with a transparent and goal-oriented approach, laying a foundation of trust and reliability.
One of the primary strategies employed to communicate effectively with stakeholders is the establishment of regular, structured interactions. This includes frequent meetings, detailed progress reports, and open channels of communication. By maintaining this level of engagement, stakeholders are kept informed about the developments and any potential challenges that may arise. These interactions are critical in aligning the project’s objectives with stakeholder expectations, thereby minimizing discrepancies and fostering a sense of partnership.
Managing stakeholder expectations is another crucial aspect. This involves a meticulous understanding of their requirements and the constraints within which the project operates. By setting realistic goals and delivering on promises, the trust and confidence of stakeholders are reinforced. The author’s approach to managing these expectations is characterized by their ability to balance immediate needs with long-term objectives, ensuring that the solutions provided are not only compliant but also sustainable.
Compliance management is seamlessly integrated into the stakeholder engagement process. Through a proactive stance on regulatory adherence, stakeholders are assured that their investments are protected from legal and operational risks. This is achieved by staying abreast of the latest regulatory changes and embedding compliance into every phase of the DevSecOps lifecycle. Examples of successful engagements include instances where the author has navigated complex regulatory landscapes to deliver solutions that are both innovative and compliant, thereby exceeding stakeholder expectations.
Ultimately, the goal is to deliver exceptional service, resources, and methods that align with the business objectives of stakeholders. By adopting a strategic and empathetic approach to stakeholder relationships, the author demonstrates a profound understanding of their needs, ensuring that each engagement is a step towards collective success.
Satyajit Ranjeev and I had the pleasure of attending the Amazon Web Services (AWS) FSI Forum in Berlin. The AWS FSI Forum is dedicated to inspiring and connecting the Financial Services community in Germany, Austria and Switzerland.
M. Reza and Satyajit took to the stage to share their insights from Solaris’ migration journey to AWS, highlighting how it has fundamentally transformed our infrastructure and service security from the ground up, improving our foundational technologies and fostering an architectural evolution.
“Our deeper engagement with AWS technologies has enabled us to develop solutions that benefit our partners and customers alike. An added advantage of our AWS integration has been our ability to manage and even reduce the costs associated with infrastructure and maintenance without compromising service quality.”
a. AWS SSO can only be used with AWS Control Tower in the same AWS Region.
b. AWS SSO can be associated with only one AWS Control Tower instance at a time.
c. AWS SSO can only federate with one external identity provider (IdP) at a time.
Azure Active Directory (AAD) Limitations:
a. Azure AD can only be used as an external identity provider (IdP) with AWS SSO, which then integrates with AWS Control Tower.
b. Azure AD must be configured as a SAML-based IdP to integrate with AWS SSO.
c. There might be certain limitations or restrictions specific to Azure AD features or configurations when used in conjunction with AWS SSO.
Control Tower Limitations:
a. Control Tower supports only SAML-based federation for single sign-on (SSO) with AWS SSO.
b. Control Tower doesn’t support other identity federation protocols like OpenID Connect (OIDC).
c. Control Tower currently supports only one AWS account as the management account.
Miscellaneous Limitations:
a. Ensure compatibility of SAML versions between AWS SSO and Azure AD. AWS SSO supports SAML 2.0, but Azure AD might support multiple versions. Verify compatibility and adjust SAML configurations accordingly.
Considerations:
When configuring AWS Control Tower with AWS SSO and Azure Active Directory (AAD), there are several considerations to keep in mind:
Identity Source and User Management:
a. Decide on the primary identity source for user management. In this case, it would be either AWS SSO or Azure AD. Consider factors such as user provisioning, synchronization, and group management capabilities each identity source provides.
b. Determine how AWS SSO and Azure AD will synchronize user accounts and groups. This can be done manually or by leveraging automation tools like AWS Directory Service or Azure AD Connect.
SAML Configuration:
a. Ensure that the SAML configurations between AWS SSO and Azure AD are compatible. Verify the SAML versions supported by each service and adjust the configuration accordingly.
b. Pay attention to the SAML attributes and claims mapping to ensure that user attributes like usernames, email addresses, and roles are correctly mapped and passed between the services.
Security and Access Control:
a. Define appropriate access controls and permissions for users and groups in both AWS SSO and AWS Control Tower. This includes assigning roles and policies within AWS Control Tower to ensure proper access to resources and guardrails.
b. Implement multi-factor authentication (MFA) to enhance security for user access to AWS Control Tower and associated AWS accounts.
c. Regularly review and update user access permissions as needed, especially when user roles or responsibilities change.
Regional Considerations:
a. Keep in mind that AWS SSO and AWS Control Tower need to be set up in the same AWS Region. Consider the availability and performance requirements of your AWS resources and choose the appropriate AWS Region for deployment.
b. Consider any data residency or compliance requirements when selecting the AWS Region and configuring AWS Control Tower and associated services.
Monitoring and Auditing:
a. Implement logging and monitoring solutions to track user access, changes to permissions, and any suspicious activities within AWS Control Tower and associated AWS accounts.
b. Regularly review audit logs and generate reports to ensure compliance with security and regulatory requirements.
Documentation and Training:
a. Document the configuration steps, settings, and any customizations made during the integration process for future reference.
b. Provide training and guidance to users, administrators, and support teams on using and managing AWS Control Tower, AWS SSO, and Azure AD integration.
Configuration:
To configure AWS Control Tower with AWS Single Sign-On (SSO) and Azure Active Directory (AAD), you need to follow these steps:
Set up AWS Control Tower:
a. Log in to your AWS Management Console.
b. Navigate to the AWS Control Tower service.
c. Follow the provided documentation or wizard to set up AWS Control Tower in your AWS account. This includes setting up the Control Tower lifecycle, organizational units (OUs), and guardrails.
Set up AWS SSO:
a. Navigate to the AWS SSO service in the AWS Management Console.
b. Follow the documentation or wizard to set up AWS SSO in your AWS account.
c. Configure user attributes and identity sources as required.
Set up Azure Active Directory (AAD):
a. Log in to the Azure portal.
b. Navigate to Azure Active Directory.
c. Follow the documentation or wizard to set up Azure AD in your Azure subscription.
d. Configure user attributes and identity sources as required.
Set up federation between AWS SSO and AAD:
a. In the AWS SSO console, go to Settings.
b. Under Identity Source, choose “Add new identity source.”
c. Select “SAML” as the type and provide a name for the identity source.
d. Download the AWS SSO metadata file.
e. In the Azure portal, go to Azure Active Directory.
f. Navigate to the Enterprise applications section and select “New application.”
g. Choose “Non-gallery application” and provide a name for the application.
h. Under Single sign-on, select SAML.
i. Upload the AWS SSO metadata file.
j. Configure the SAML settings according to the AWS SSO documentation.
k. Save the SAML configuration.
Assign users and groups to AWS Control Tower:
a. In the AWS SSO console, go to the AWS accounts tab.
b. Select the AWS Control Tower account and click on “Assign users/groups.”
c. Choose the appropriate users and groups from the AWS SSO directory.
d. Grant the necessary permissions for Control Tower access.
Test the configuration:
a. Log in to the Azure portal using an account from AAD.
b. Navigate to the AWS Management Console using the AWS SSO link.
c. You should be able to access Control Tower resources based on the assigned permissions.
Intellectual dishonesty at the workplace can have significant impacts on individuals, teams, and the overall work environment. Here are some potential impacts:
Trust and credibility: Intellectual dishonesty erodes trust among colleagues and undermines the individuals’ credibility. When people engage in dishonest behavior such as lying, plagiarism, or misrepresenting information, others may question their integrity and become skeptical of their actions and words.
Collaboration and teamwork: Intellectual dishonesty can hinder effective collaboration and teamwork. When individuals are not honest about their knowledge, skills, or contributions, it can lead to misunderstandings, conflicts, and a breakdown in communication. Trust and collaboration are vital for building strong, cohesive teams.
Quality of work and decision-making: Intellectual dishonesty can compromise the quality of work and decision-making processes. Misrepresented or manipulated information can result in flawed analysis, inaccurate reports, and poor decision-making. Intellectual honesty is crucial for maintaining the accuracy and reliability of work outcomes.
Ethical and moral implications: Intellectual dishonesty goes against ethical and moral principles. It can create a negative work culture where individuals prioritize personal gain over the organization’s and its stakeholders’ well-being. Engaging in dishonest practices can damage one’s reputation and have legal consequences.
Employee morale and motivation: Intellectual dishonesty can lower employee morale and motivation. When individuals observe dishonest behavior in the workplace, it can create a toxic work environment, leading to demotivation, disengagement, and a decline in productivity. Employees may feel disillusioned and lose their enthusiasm for their work.
Organizational reputation: Intellectual dishonesty can have a detrimental impact on the reputation of the organization. If dishonest practices are exposed or known within the industry or among clients, it can damage the organization’s credibility, brand image, and stakeholder relationships. It may also lead to legal and regulatory consequences.
To maintain a healthy work environment, it is essential for individuals and organizations to promote intellectual honesty, transparency, and integrity. By encouraging open communication, fostering a culture of honesty, and implementing policies that discourage dishonest behavior, organizations can mitigate the negative impacts of intellectual dishonesty and promote a positive and ethical workplace.
How to avoid intellectual dishonesty at the personal level?
Avoiding intellectual dishonesty requires self-awareness, personal integrity, and a commitment to ethical behavior. Here are some ways that individuals can avoid intellectual dishonesty:
Commit to honesty and integrity: Make a conscious decision to prioritize honesty and integrity in your work and interactions. Understand that intellectual dishonesty not only harms others but also undermines your own credibility and reputation.
Be aware of biases and cognitive distortions: Recognize your own biases, prejudices, and cognitive distortions that may cloud your judgment or lead to intellectual dishonesty. Strive to approach situations with an open mind, consider different perspectives, and challenge your own assumptions.
Seek and respect diverse viewpoints: Actively seek out diverse viewpoints, opinions, and feedback. Engage in respectful discussions and debates, and be open to changing your opinions or beliefs based on new information or evidence. Avoid dismissing or ignoring perspectives that differ from your own.
Verify information and sources: Review the information before accepting it as true or using it in your work. Double-check facts, consult reliable sources, and critically evaluate the information’s credibility and trustworthiness.
Give credit and acknowledge sources: When using or referencing the work or ideas of others, give proper credit and acknowledge the original sources. Plagiarism is a form of intellectual dishonesty that should be strictly avoided. Cite references, provide attributions, and follow ethical academic or professional writing guidelines.
Be transparent about limitations and uncertainties: Be transparent about your work’s limitations, uncertainties, and assumptions. Clearly communicate any gaps in knowledge, potential biases, or areas where further research or analysis is required. Avoid presenting information as definitive or conclusive when it is not.
Admit mistakes and learn from them: If you make an error or realize that you were intellectually dishonest, admit your mistake, apologize if necessary, and take corrective actions. Learn from the experience and use it as an opportunity to grow, improve your integrity, and become more mindful of ethical behavior.
Seek feedback and accountability: Encourage others to provide feedback on your work and behavior. Surround yourself with people who hold you accountable for your actions and are willing to challenge you when they perceive intellectual dishonesty. Actively engage in self-reflection and welcome constructive criticism.
By practicing these principles, individuals can cultivate a culture of intellectual honesty and ethical behavior in their personal and professional lives. It promotes trust, fosters healthy relationships, and contributes to a positive and productive work environment.
When we architect the application, it is essential to consider the current metrics and monitoring logs to ensure its design is future-proof. But sometimes, we do not have the necessary logs to make the right decisions. In that case, we will let the application run in an architecture that we think seems optimized – using the metrics we had access to – and let it run for a while to capture logs required to apply necessary changes. In our case, the application has grown to the point where we could not expect it to happen!
The COVID-19 has increased the consumption of all online applications and systems in the organization, whether modern or legacy software.
We have an application that is spanned across three availability zones with EFS mount points in each AZ retrieving data from and Amazon Aurora Serverless. In the past two weeks, we realized the application is getting slower and slower. Checking the EC2 and database activity logs did not help, and we learned something could be wrong with the storage. Unexpectedly, the issue was, in fact, caused by the EFS limitation for I/O on general-purpose performance mode.
In General Purpose performance mode, read and write operations consume a different number of file operations. Read data or metadata consumes one file operation. Write data or update metadata consumes five file operations. A file system can support up to 35,000 file operations per second. This might be 35,000 read operations, 7,000 write operations, or a combination of the two.
After creating an EFS file system, you cannot change the performance mode, and with having almost 2 TB of data in the file system, we were concerned about the downtime window. AWS suggests using AWS DataSync to migrate the data from either on-premises or any of the AWS storage offerings. Although DataSync could offer help to migrate the data, we already had AWS Backup configured. So, we used AWS Backup to take a complete snapshot of the EFS and restore it as a Max I/O file system.
Note that Max I/O performance mode offers a higher number of file system operations per second but has a slightly higher latency per each file system operation.
Communication is the activity or process of expressing ideas and feelings or of giving people information; “an apparent answer to the painful divisions between self and other, private and public, and inner thought and outer word.”. According to the Oxford dictionary, communication means “the activity or process of expressing ideas and feelings or giving people information” (Peters, 1999).
However, in reality, communication is not just about the transmission of information amongst people. It starts with the willingness to initiate this transmission of info.
if the transmitter of information does not believe that the information will be actred upon or that it is not wanted, it will not be passed on – motivation to communicate will not exist.
(Knowles, 2011)
In an organization, if all levels of hierarchy believe that the top management must make the decisions due to the existence of power right at the top of the ranking, the communication at lower levels will eventually stop, which results in maladjusted decision making at all levels. The transmission of information shall not be considered the escalation of decision making. But instead, the information must be taken seriously, and superiors must not suggest a decision by receiving the passed-on information.
the organizational structure alone will not ensure a free flow of information – the will to communicate must be there too. This is, therefore, a cultural issue. Everyone in the organization has the responsibility to act on, pass, seek and receive information and there is no possibility to pass the responsibility to anyone else.
(Knowles, 2011)
The organization education concerning a free and speedy course of information transmission is the “heart of empowerment.”
the organization functioning as a holistic process rather than a hierarchy based on functional power bases.
(Knowles, 2011)
The information flow and decision-making process mustn’t follow the chain of command at all times. One way to improve the transmission of the knowledge and flow of information is to avoid 1-on-1 email communications and use tools like organization-wide wikis to share meeting notes, decisions, goals, plans, policies, etc.
References
Peters, J. D. (1999). Speaking into the air: A history of the idea of communication. Chicago: University of Chicago Press.
Knowles, G. (2011). Quality Management. Graeme Knowles & Ventus Publishing APS, USA.